 Jellyfin 豆瓣元数据插件
Jellyfin 豆瓣元数据插件
电脑组装了半年了,硬盘里也存了不少番剧、日剧和电影,所以我打算整理一下,搭个媒体库。原本是想用Emby,但是这玩意稍微搞点啥操作都要会员,搞不懂了,又不用你家服务器还要开会员?后来发现Emby原来是开源的,后来闭源了,而Jellyfin就是从Emby最后一个开源版本演化过来的。开源软件,好!闭源软件,不好!
不过Jellyfin只是个媒体库平台,视频还是需要自己提供,并且需要对视频按照文件夹分类。分好类之后还需要想办法收集元数据,这样才能在Jellyfin里看到漂亮的封面和简介。Jellyfin官方提供了一个TMDB网站的元数据插件,但因为众所周知的原因不太好用。也有人开发了用于豆瓣的元数据插件jellyfin-plugin-opendouban,我试了一下还不错,不过因为要起一个Docker,稍微有些麻烦。于是我参考了这个插件以及bgm.tv的元数据插件jellyfin-plugin-bangumi,自己写了一个豆瓣元数据插件出来。
功能和特性
相较于jellyfin-plugin-opendouban,本插件增加了一些功能和特性以增强体验:
- 无需额外运行Docker容器,对Windows用户更友好。
- 搜索时根据“电影”或“电视剧”分类进行排序,避免关联到不恰当的条目。例如,当前(2023年11月6日)直接搜索《名侦探柯南》得到的第一条结果是电影《名侦探柯南 黑铁的鱼影》而不是动画《名侦探柯南》,这可能是考虑到了最新作电影更有人气而将搜索顺位提前,但是对于收集元数据来说很不方便。而进行排序后,如果指定视频类型为“节目”,则会将分类为“电视剧”的条目排在前面,就可以得到正确的结果。
- 对元数据中标题的处理更加准确。当影视的译名中存在空格时,原插件无法准确识别原名和译名的分割,而本插件通过其他标签辅助判断,能够推断出准确的原名和译名。
- 使用内置Api和AnitomySharp根据文件名判断视频标题,搜索结果更加准确。
- 增加了对单集剧集的元数据的支持。但据我个人的使用经验,豆瓣的单集剧集的条目内容良莠不齐,有些集数的介绍甚至是对剧情的吐槽,所以请自行选择是否开启。
- 支持访问速率控制,并且内置了缓存机制,避免频繁访问豆瓣服务器导致被封禁。
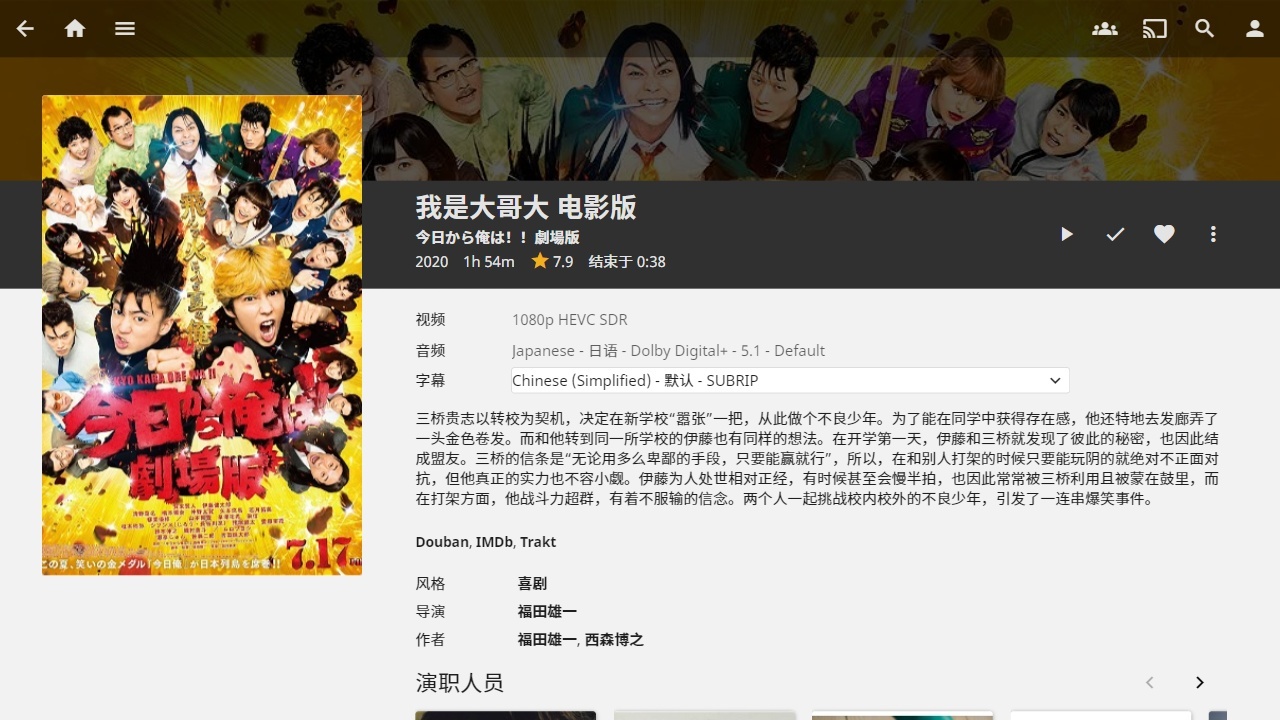 获取元数据后的效果
获取元数据后的效果
安装方式
注意:对于Jellyfin 10.10.x版本,请使用本插件的3.x版本;对于Jellyfin 10.11.x及更高版本,请使用本插件的4.x版本。
插件库
手动安装
- 下载插件压缩包,将dll文件解压至
<Jellyfin 数据目录>/Plugins/Douban。
- 重启Jellyfin。
使用方法
- 在Jellyfin控制台中选择“豆瓣设置”,根据需要调整选项。关于“Cookie”和“豆瓣图片服务器”的填写请参见“关于速率限制”部分。其他选项的含义在设置页均有说明。
- 对于还未添加的媒体库,请在添加媒体库时选择“Douban”作为元数据下载器,并按照需求调整优先级。最上方的下载器优先级最高。注意在选择类型时,电视剧、连载动画等拥有多集的视频请选择“节目”类型,电影、OVA等单集视频请选择“电影”类型。如果类型选择错误,可能会导致搜索结果不准确。
- 对于已添加的媒体库,请在媒体库设置中选择“Douban”作为元数据下载器,并按照需求调整优先级。然后进入媒体库主页,点击右上角的“…”按钮,选择“刷新元数据”→“覆盖所有元数据”,即可开始获取元数据。
- 插件会根据文件夹名称自动判断视频标题并进行搜索。如果文件夹标题中包含豆瓣ID(格式为
[douban=数字],例如名侦探柯南 (1996) [douban=1463371]),则会直接使用该ID进行搜索。
已知问题
关于速率限制
由于豆瓣目前已经没有公开的api,所有请求均基于直接获取相关网页,过快的访问速率可能会被视为恶意爬取软件而被封禁。为了尽可能避免被封禁,请尝试调整设置选项:
- 增加每两次请求之间的时间间隔。默认设置为2秒。
- 填入Cookie。请使用浏览器打开豆瓣电影并登录,然后按F12打开控制台,选择
Network,刷新页面,选择movie.douban.com,在右侧的Headers中找到Cookie,复制其内容并填入设置选项中。
此外,在不带Referer获取豆瓣的图片时会被限速至10KB/s左右,这可能会导致获取元数据时超时,部分剧集无法正常显示。可在本插件的设置中取消“在影视页面获取演职员照片”的勾选,这可以防止Jellyfin在获取影视元数据时大量获取演职员的图片导致超时。
速率限制可以通过搭建反代来回避,插件自带了一个反向代理,可在设置选项中修改“豆瓣图片服务器”使用。例如,如果服务器地址为http://localhost:8096/,则本插件的反代地址为http://localhost:8096/Plugins/Douban/Image?url=(注意最后有一个等号 =)。
也可以自行搭建反代,以下是一个简单的nginx本地搭建反代的配置文件示范:
复制代码- server {
- listen 80;
- listen [::]:80;
- charset utf8;
- server_name doubanio.localhost;
- location / {
- proxy_pass https://img2.doubanio.com;
- proxy_set_header Host img2.doubanio.com;
- proxy_set_header Referer https://movie.douban.com/;
- }
- }
部分影视无数据
豆瓣限制了部分影视仅在登录状态下可见(例),这可能导致部分影视无法获取到元数据。如果遇到这种情况,请登录并填入Cookie(参见上一步),或者手动填写豆瓣ID。
季的内容为空
由于Jellyfin自身的缺陷,如果将视频文件直接存放在一级子目录下(例如/(根目录)/剧名/[XXSub] Bangumi Name - 01.mp4),Jellyfin会自动生成一个季,导致插件的解析出现错误。3.3.1版本已尝试修复了此问题,但仍可能存在问题。建议将视频文件存放在季的子目录下(例如/(根目录)/剧名/第1季/[XXSub] Bangumi Name - 01.mp4,参考资料)。
手动搜索id时没有结果
请确保你把id填在了“Douban 电视节目 Id”或“Douban 电影 Id”里,而不是填在了“名字”里。
如果你不想这么麻烦,也可以将文件夹重命名一下,在文件夹名中包含[douban=数字],例如名侦探柯南 (1996) [douban=1463371],插件会自动识别。
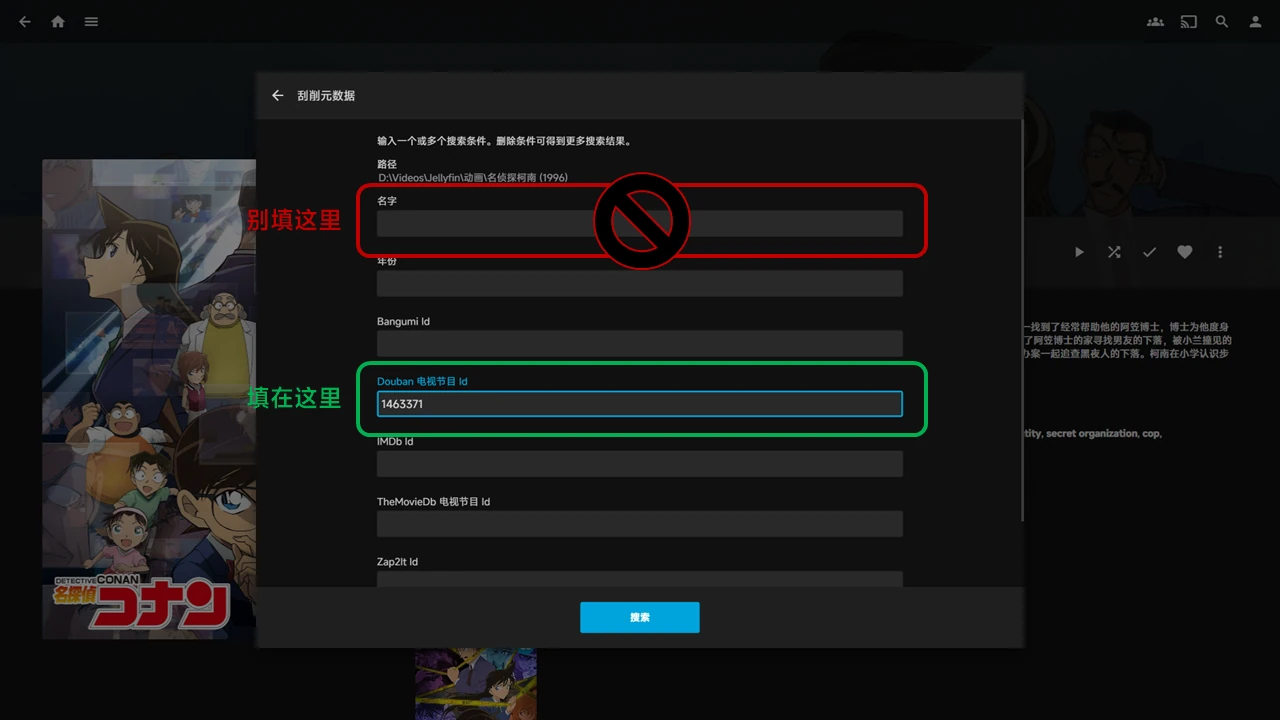 填写id的位置
填写id的位置
更新日志
见此。
写在最后
感谢两个插件的作者对本插件的启发。
如有任何问题,请在下方评论区提出,或在GitHub仓库中提交issue。