 《灵异视界 FILE23 本所七大不可思议》汉化笔记
《灵异视界 FILE23 本所七大不可思议》汉化笔记
本来我没打算买这个游戏,不过我有一个朋友说对这个游戏感兴趣,我就顺便研究了一下。
文件格式
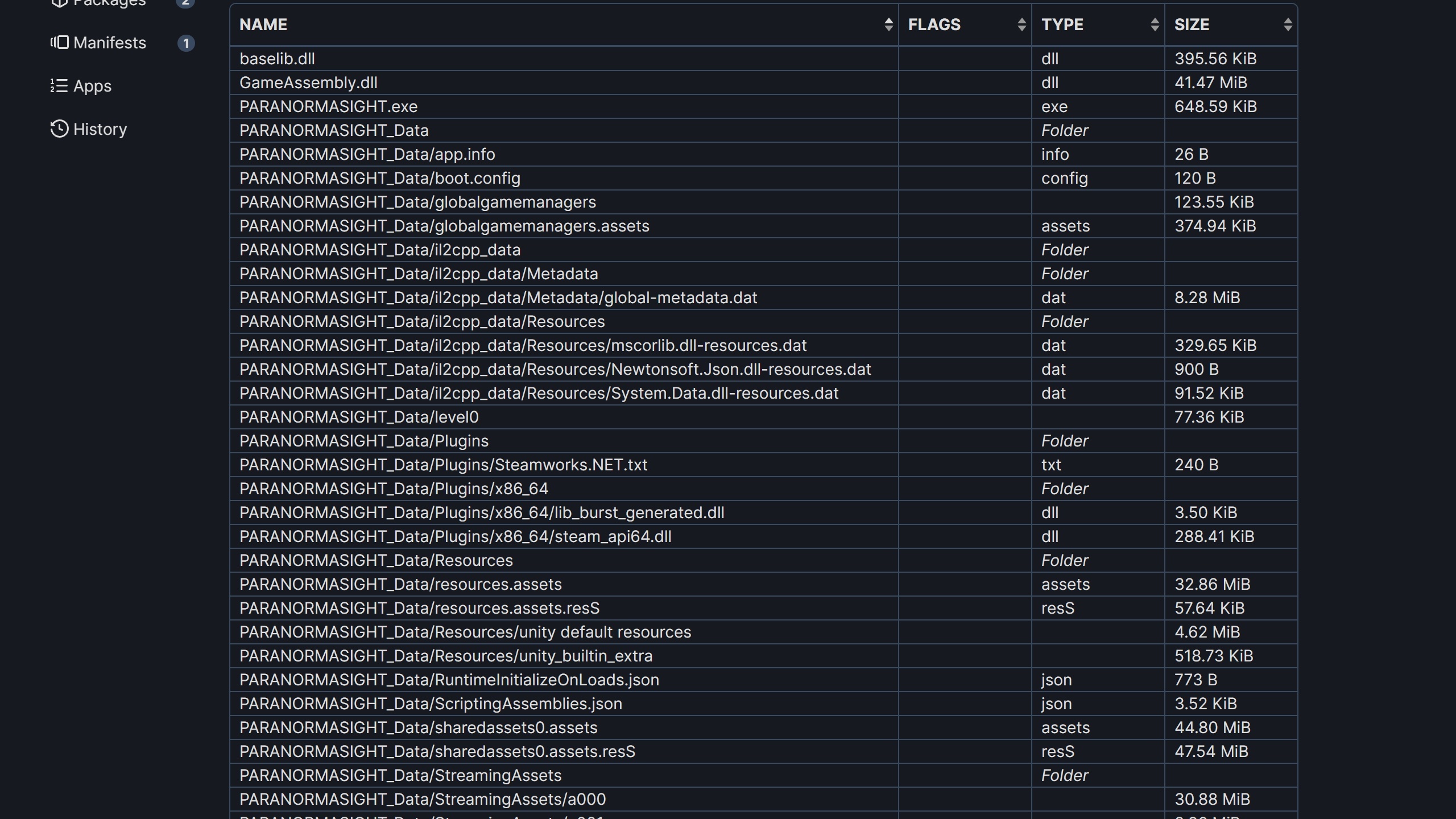 游戏的文件结构,来自SteamDB
游戏的文件结构,来自SteamDB
拿到游戏文件后一看结构,“PARANORMASIGHT_Data”“StreamingAssets”几个文件夹直接蹦了出来,一看就知道是Unity做的游戏。直接拿AssetStudio读取一下,从PARANORMASIGHT_Data/resources.assets、PARANORMASIGHT_Data/sharedassets0.assets里找到了TextMesh Pro的字体文件。这个插件我也不是第一次接触了,之前我就写过用这个插件修改字体的文章。实际上就是用这个插件拿中文字体重新生成一个字体,然后替换掉原字体的相关信息,再打包回去就行了。
但是这两个文件显然没有包含全部游戏内容,继续寻找,发现在PARANORMASIGHT_Data/StreamingAssets/文件夹下有很多诸如a001、a002文件名的文件。拖到AssetStudio里没法直接打开它,拿HxD一看,发现了UnityFS的文件头。推测是在Unity的文件格式外面又套了一层不知道什么格式,因此直接尝试简单粗暴的办法,去掉UnityFS文件头前面的字节序列,然后把它当成Unity的打包文件修改,修改之后再把字节序列加回去。尝试了一下,这样操作完之后游戏仍然可以读取这个文件,因此勉强能用。
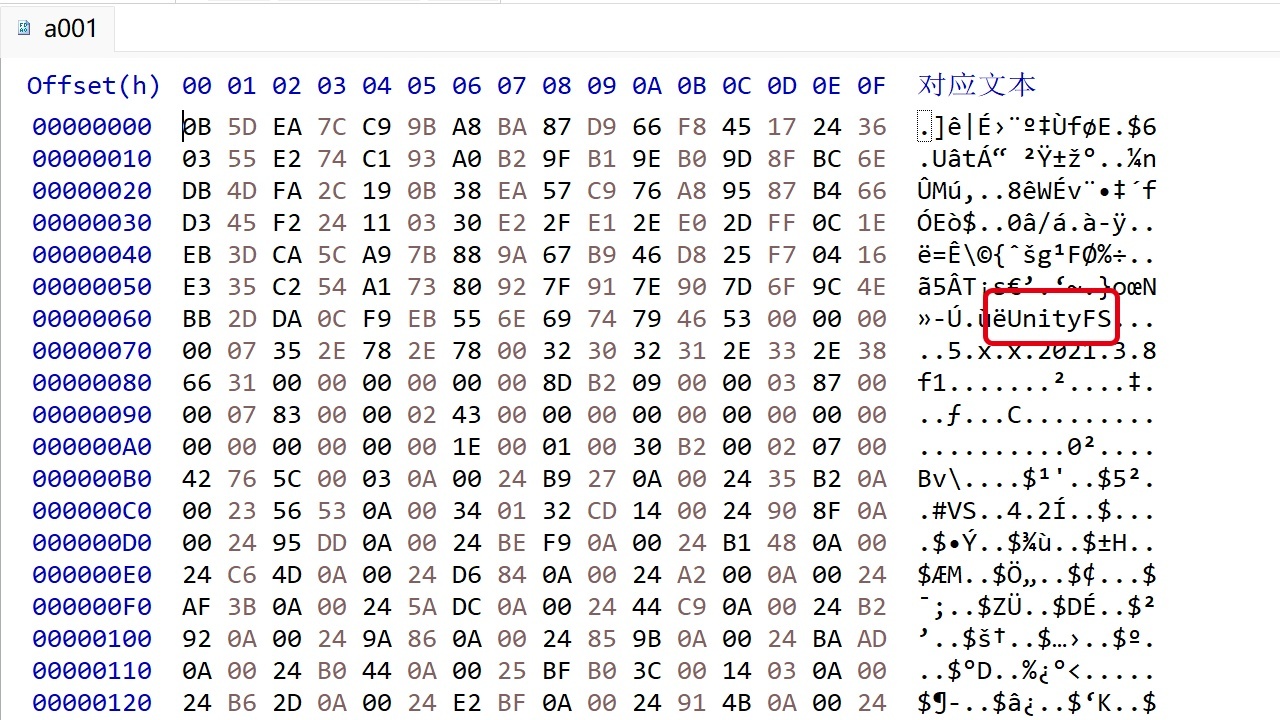 用HxD查看文件结构
用HxD查看文件结构
批量去除UnityFS前的字节序列后,得到了35个文件。为了汉化,我需要关注的是字体和文本。在简单查找并确认后,我发现字体文件位于a021、a035、a038中,而文本位于a024、a036中。字体同样实用的TextMesh Pro,按照前面所说的方式修改即可。
文本导出
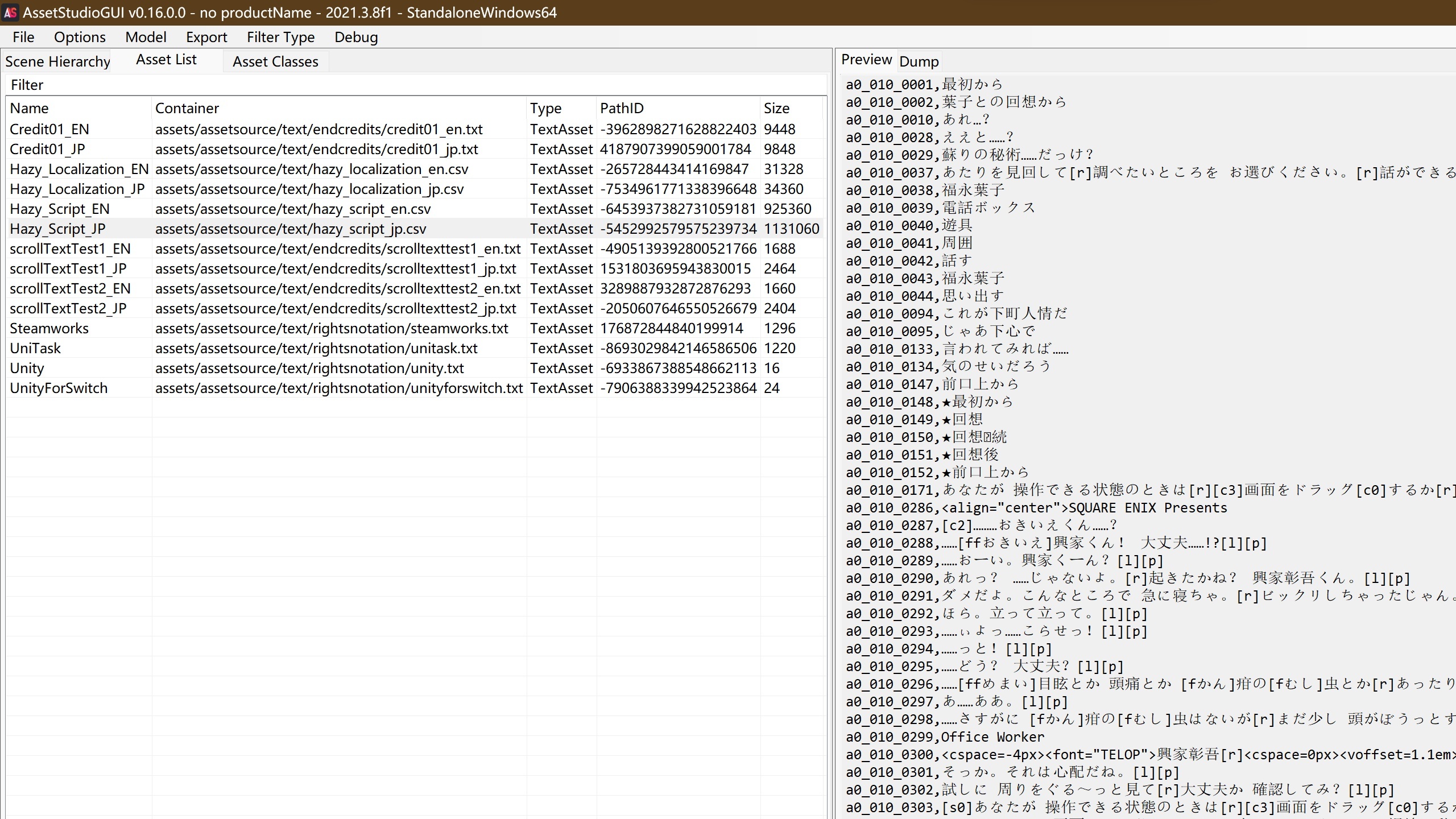 a036
a036
首先关注的是a036文件中的文本。这个文件中包含了Hazy_Localization_JP和Hazy_Script_JP等文本文件,从名字上来看应该就是游戏的文本了。解析起来也不困难,是类似于csv的格式,每行用逗号分隔了文本id和文本内容。虽然看上去像csv,但实际上不能用csv的解析器解析,因为部分文本里面有引号,还有部分文本里有逗号,所以真的只是“类似于csv”而非“就是csv”。
导出,修改,导入——这是最简单的流程。但是导入之后发现了新的问题,修改英文文本可以直接显示出来,但是修改日文文本是没有效果的。
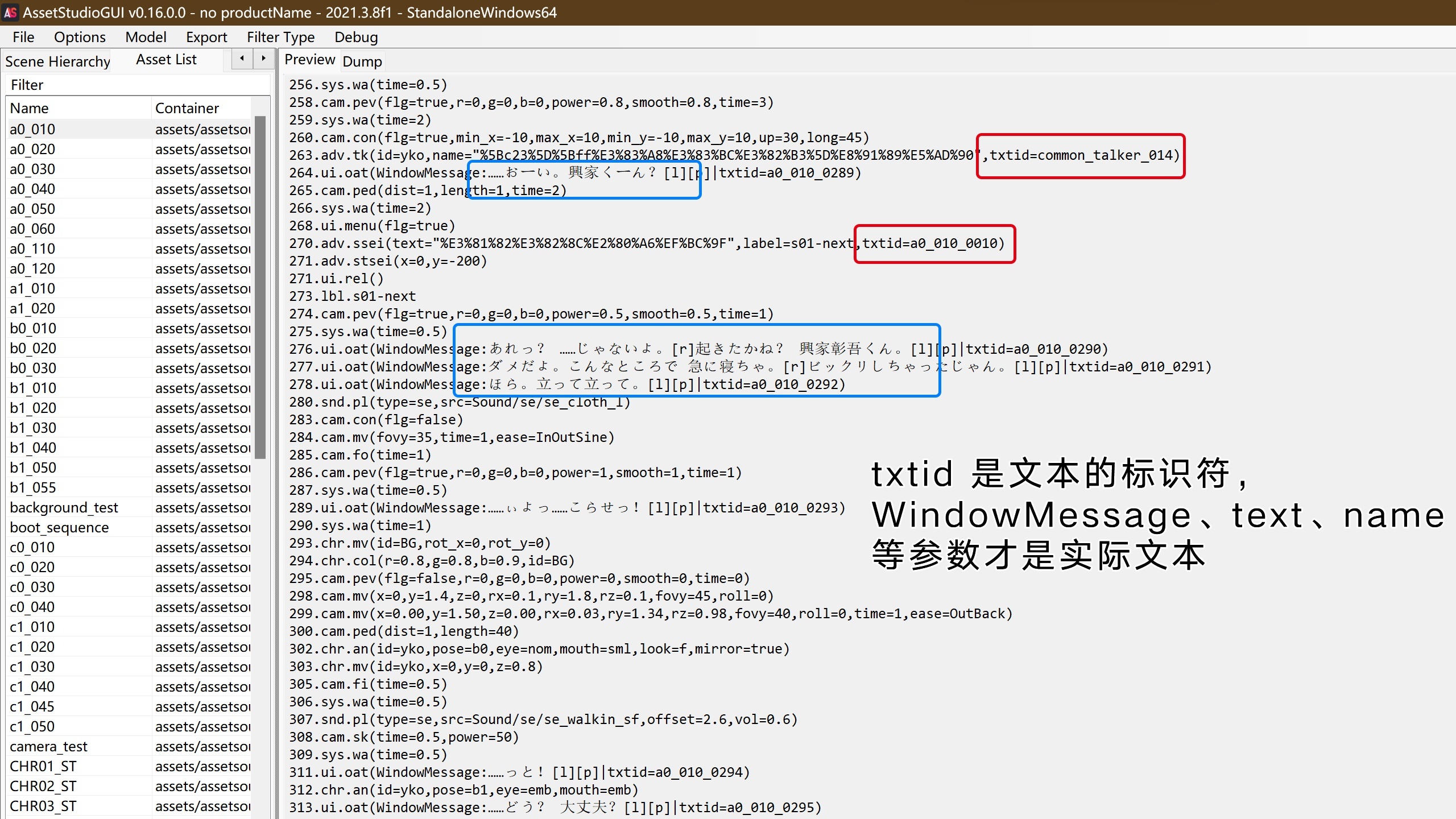 a024
a024
再检查一下a024文件,这个文件包含的文本是游戏的运行脚本,里面包含了文本id和显示方式。考虑到这是个日本游戏,可以猜测这个游戏的日文版实际上是直接从脚本里读取文本的,而不是从a036文件中读取的。因此,如果要基于日文制作汉化的话,需要修改这些运行脚本。并且,游戏脚本中有一些基于游戏语言的判断,在日文和英文条件下文本的显示位置和内容都有细微的差异,但却共用了同一个id。离谱的是,我自己的编写程序从这些脚本中导出的文本实际上与a036文件中导出的文本不一致,推测是开发过程中修改了运行脚本但却没有再次导出日文文本(因为实际用不上)。于是我自己实现了文本的导出,并根据新导出的文本制作汉化。
快速机翻
导出文本之后,还要对文本进行翻译。粗略算了一下,需要翻译的文本大概有40万个字符(VS Code数据),全靠人工翻译不太现实,就需要用到机翻了。对于中文↔日文翻译来说,Google翻译、必应翻译和DeepL的效果都很差,因为他们都会先把文本翻译成英文,经过两次转手的翻译结果简直没法看。在经过了对比之后,我决定选择百度翻译和有道翻译,然后对比两种翻译,选取“比较好的”。
关于两种翻译的使用方式,百度翻译有官方的API,个人开发者注册并进行实名认证后可以享受“高级版”服务,每月免费使用量为100万字符。而有道翻译的官方API没有每月的免费额度,只是初次注册时送10元的试用额度。当然,能免费用的话还是免费用比较好,所以我还是更喜欢百度翻译一些。不过有道翻译的质量也不差,因此还是需要想办法把它也用上。
经过了一些测试,我最终采用了这样的工作流程:
- 将全部文本提取出来,然后将一些片假名专有名词替换为对应的汉字,例如
ヒハク→飛白。
- 将替换专有名词后的文本按标点符号分割为句子。标点分割的正则表达式:
re.compile(r"^[^。!?…\!\?\\]*[。!?…\!\?]+[」』”’〜)]?")。
- 将所有句子去重后,按照字典序排序,然后按照每1000行句子为一组,分别写入到多个文件中。
- 对分割后的文件进行百度翻译或有道翻译,先用日翻中获得中文,再用中翻日获得日文。
- 使用Python自带的
difflib.SequenceMatcher函数,对原文和两次翻译后获得的日文进行对比,认为相似度较高的翻译算是“比较好的”。将两种翻译及其相似度保存到数据库中。
- 将“比较好的”翻译结果按照原文拼接出译文,然后保存成新文件,再进行人工校对。
- 校对过程中,如果发现了新的专有名词,就将其加入到专有名词字典中,然后重新进行步骤1;只是无需再将数据库中已翻译过且未修改的句子再次翻译,节省成本。
关于人工校对的方式,我采用了Weblate,这是一个开源的翻译平台,可以用来管理翻译项目。由于Weblate对导入和导出的文件格式有一定要求,为了充分利用Weblate的功能,我加了一道转换过程,将游戏文本转换成了Weblate可识别的csv文件,并对Weblate的代码进行了少许定制。然后,我在GitHub上创建了一个翻译项目,并使用了多个分支,其中master分支是构建补丁所用的文件,weblate分支是喂给Weblate的文件。之后,在Weblate上创建一个项目,并将weblate分支的文件导入进去,就可以开始翻译了。翻译完成后,Weblate会自动将译文推送到GitHub的weblate分支,通过GitHub Actions的自动部署更新master分支,然后自动构建补丁并发布。
导入翻译后的效果