NDS平台的《世界树的迷宫》有三作,然而只有前两作有汉化,第三作迟迟没有汉化。正好三作合集的高清重制版发售了,并且自带官中,于是想到可以把官中的文本逆向移植到NDS版。这里就简单记录一下如何做到的。
文件结构
与前两作不同的是,本作采用了Atlus自研的打包格式,数据文件被放在了Data/Target.bin、Data/Target.idx、Data/Target.ndx三个文件中。好在这个格式已经有了提取工具,因此就不用重复造轮子了。
将文件提取出来之后,可以看到Font文件夹下保存了字体,Tex文件夹下保存了贴图,而文本则分散在各个文件夹下。
图片
图片格式可以用Tinke处理,这篇帖子给出了解决方案,照做即可。图片的处理脚本见此。
文本
首先搜索文本,经过简单的排查之后,可以发现.mbm格式的文件以及一部分.tbl格式的文件里包含了文本,而编码格式是Shift-JIS格式的,因此无需码表即可提取文本。解码文本的过程中发现了一些以\x80为开头的字节,而正常情况下Shift-JIS编码并不会出现\x80字节,说明这个字节可能是控制符。由于已经有了移植版,将移植版的文本与NDS版的文本对比即可推断出各个控制符的含义。
字库
再来研究字库,Font文件夹下有几个文件:Font8x8.cmp、Font10x10.cmp、Font12x12.cmp,显然文件名就已经说明了字号大小。.cmp后缀表明这个文件可能是压缩过的,用NDS常见的LZ10算法即可解压(例如Batch LZ77,得到三个二进制文件。先研究最大的文件Font12x12.cmp.decompressed,用HxD打开发现没有明显的文件头,但是能看出来有一定的周期性:
复制代码- Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
- 00000400 04 00 04 00 02 00 00 00 00 00 20 00 20 00 20 00 .......... . . .
- 00000410 20 00 FE 03 20 00 20 00 20 00 20 00 00 00 00 00 .þ. . . . .....
- 00000420 00 00 00 00 00 00 00 00 00 00 FE 03 00 00 00 00 ..........þ.....
- 00000430 00 00 00 00 00 00 00 00 00 00 20 00 20 00 20 00 .......... . . .
- 00000440 FE 03 20 00 20 00 20 00 00 00 FE 03 00 00 00 00 þ. . . ...þ.....
- 00000450 00 00 02 02 04 01 88 00 50 00 20 00 50 00 88 00 ......ˆ.P. .P.ˆ.
- 00000460 04 01 02 02 00 00 00 00 00 00 20 00 20 00 00 00 .......... . ...
- 00000470 00 00 FE 03 00 00 00 00 20 00 20 00 00 00 00 00 ..þ..... . .....
- 00000480 00 00 00 00 00 00 FE 03 00 00 00 00 FE 03 00 00 ......þ.....þ...
- 00000490 00 00 00 00 00 00 00 00 00 00 00 03 C0 00 30 00 ............À.0.
- 000004A0 0C 00 02 00 0C 00 30 00 C0 00 00 03 00 00 00 00 ......0.À.......
- 000004B0 00 00 06 00 18 00 60 00 80 01 00 02 80 01 60 00 ......`.€...€.`.
- 000004C0 18 00 06 00 00 00 00 00 00 00 80 03 70 00 0E 00 ..........€.p...
- 000004D0 70 00 80 03 00 00 FE 03 00 00 FE 03 00 00 00 00 p.€...þ...þ.....
- 000004E0 00 00 0E 00 70 00 80 03 70 00 0E 00 00 00 FE 03 ....p.€.p.....þ.
- 000004F0 00 00 FE 03 00 00 00 00 00 00 04 01 88 00 50 00 ..þ.........ˆ.P.
拿CrystalTile2打开,切换到Tile视图,宽度和高度分别设为16和12,然后启用“左右对调”和“水平翻转”,即可看到按Shift-JIS顺序排列的字库。因此得知这个文件就是简单地保存了字符的图像数据。
至此,文本和字库的问题似乎都解决了……?并没有,由于字库本身没有保存Shift-JIS编码和字符在字体中编号的对应关系,因此游戏中肯定还有另外一个地方保存了映射表。然而在解包的文件里并没有找到类似作用的文件,arm9.bin里也没有找到按顺序排列的字符串。这时候我首先想到的是借助于IDA Pro来分析游戏的代码。
如何使用IDA Pro载入NDS文件我在之前的文章中已经说过,此处就不再重复了。只不过需要注意一下本作的可执行文件都是被压缩过的,而我暂时还没有给载入脚本添加解压缩功能,因此需要手动解压一下arm9.bin和各个overlay文件,然后重新打包一个ROM。
逆向第一步:寻找对应关系
文件载入进来了,接下来的问题是:从何入手?由于函数太多,一个一个分析显然是不现实的。分析一下游戏运行的流程,既然游戏要把文本显示在画面上,那么一定要运行载入文本→解码文本→显示文本的流程。在此过程中,内存中肯定会包含原始的Shift-JIS编码的文本。于是,拿DeSmuME打开游戏,并在开始界面显示出第一句话的时候暂停,选择“Tools”→“View Memory”→“Dump All”,将内存导出为二进制文件,再用HxD打开并搜索第一句话的文本用来定位:
 用DeSmuME导出内存
用DeSmuME导出内存
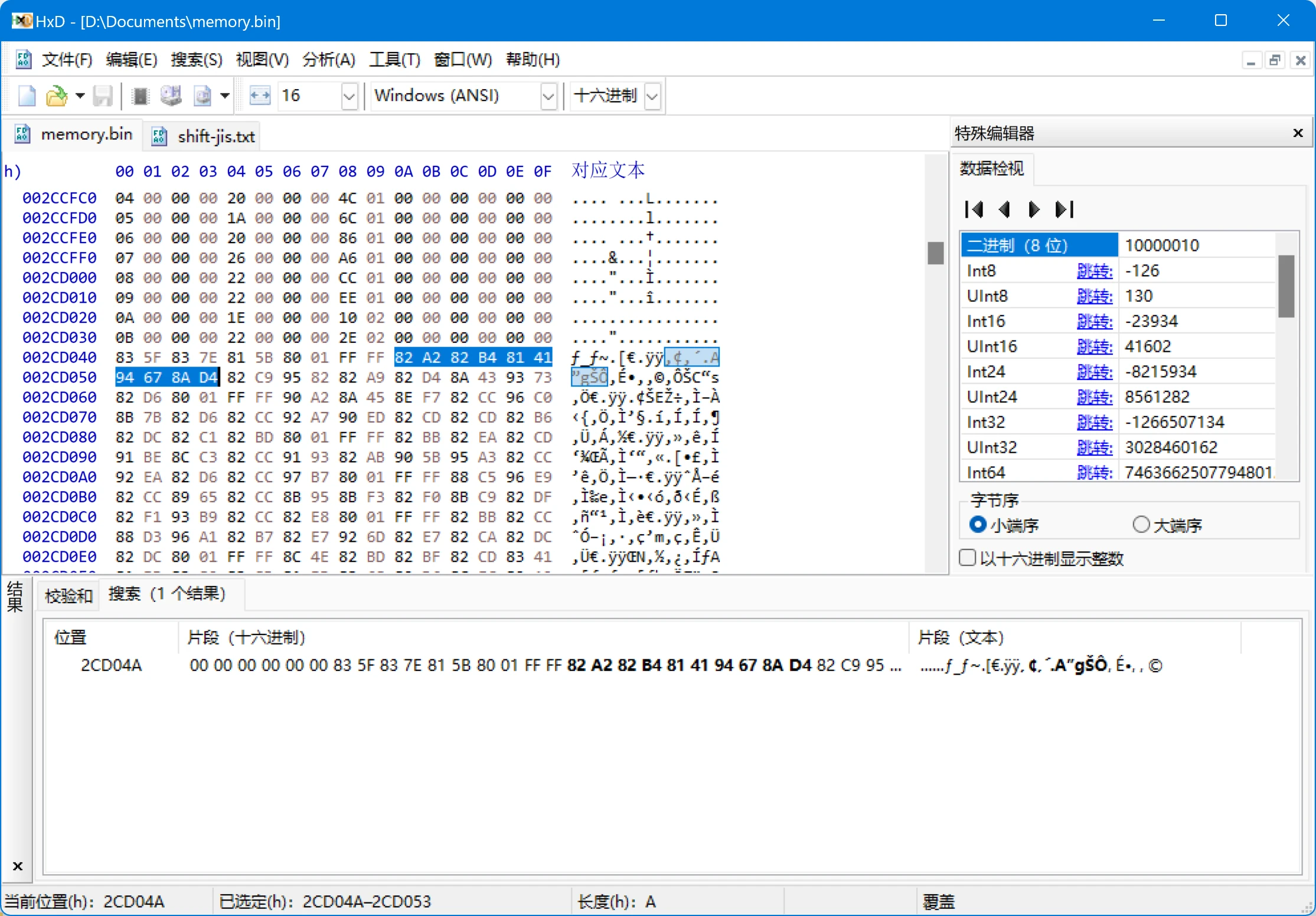 用HxD查找字节序列
用HxD查找字节序列
这里需要注意:
- DeSmuME不支持中文路径。
- HxD不支持搜索非日文字符,因此需要手动新建一个以Shift-JIS保存的文本文件,然后用HxD读取它的字节序列。如果有更好用的十六进制编辑器,也欢迎推荐给我。
- 导出的内存是从0x2000000开始的,因此在DeSmeME查看的时候要注意加上这个偏移量。
从图中可以看到在0x22CD04A(内存地址)处找到了这个字符串,因此可以在这里设置一个内存读取断点。但是需要注意的是,由于此时文本已经被显示出来了,所以猜测这个内存地址后续不会再被读取,所以需要重启游戏后再重新设置断点。具体方法是,在“Memory viewer”窗口右上角输入内存地址,然后选择“Add Read Breakpoint”。
 用DeSmuME设置内存读取断点
用DeSmuME设置内存读取断点
接下来在主窗口选择“Tools”→“Disassembler”打开反编译窗口,这里会弹出来两个窗口:ARM9 Disassembler和ARM7 Disassembler,分别对应NDS的两个CPU。通常情况下,游戏的主要逻辑都是通过ARM9来处理的,因此可以直接关掉ARM7的窗口。由于这个内存区域还被其他程序读取,所以在命中断点时还需要检查一下内存地址相关的状态。如果不是我们想要的状态,就在“ARM9 Disassembler”窗口左下角选择“Continue”,直到找到我们想要的状态。
在经过了一番筛选后,终于查到了一个比较有用的状态:
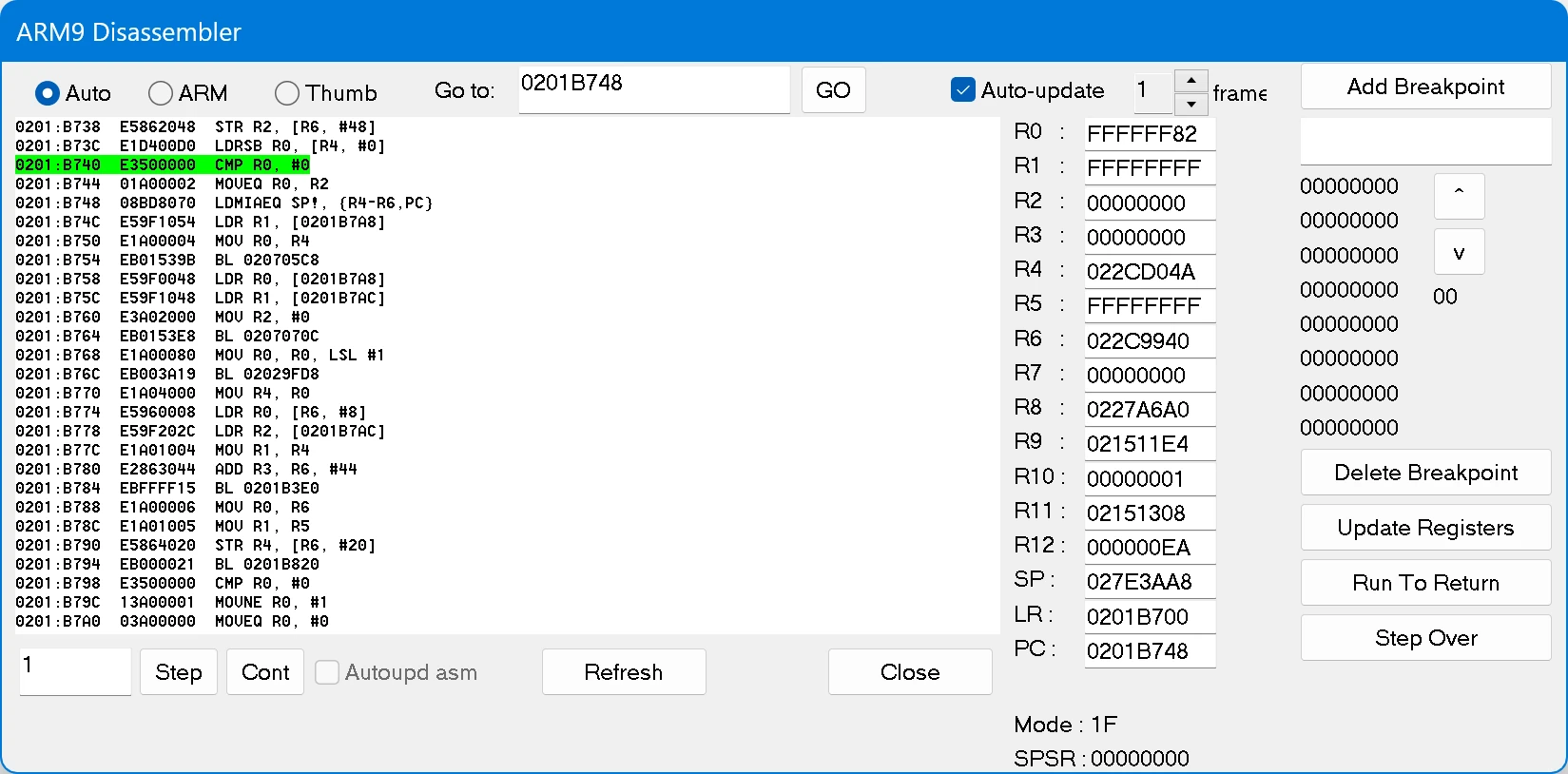 读取断点命中时的情况
读取断点命中时的情况
此处右数第二列显示出了各个寄存器的状态(实际上还有几个位寄存器没有显示出来),其中R4寄存器就是我们下断点的地址022CD04A,而PC寄存器保存了下一步将要执行的指令的地址。因此在IDA Pro中跳转到0x201B748这个地址:
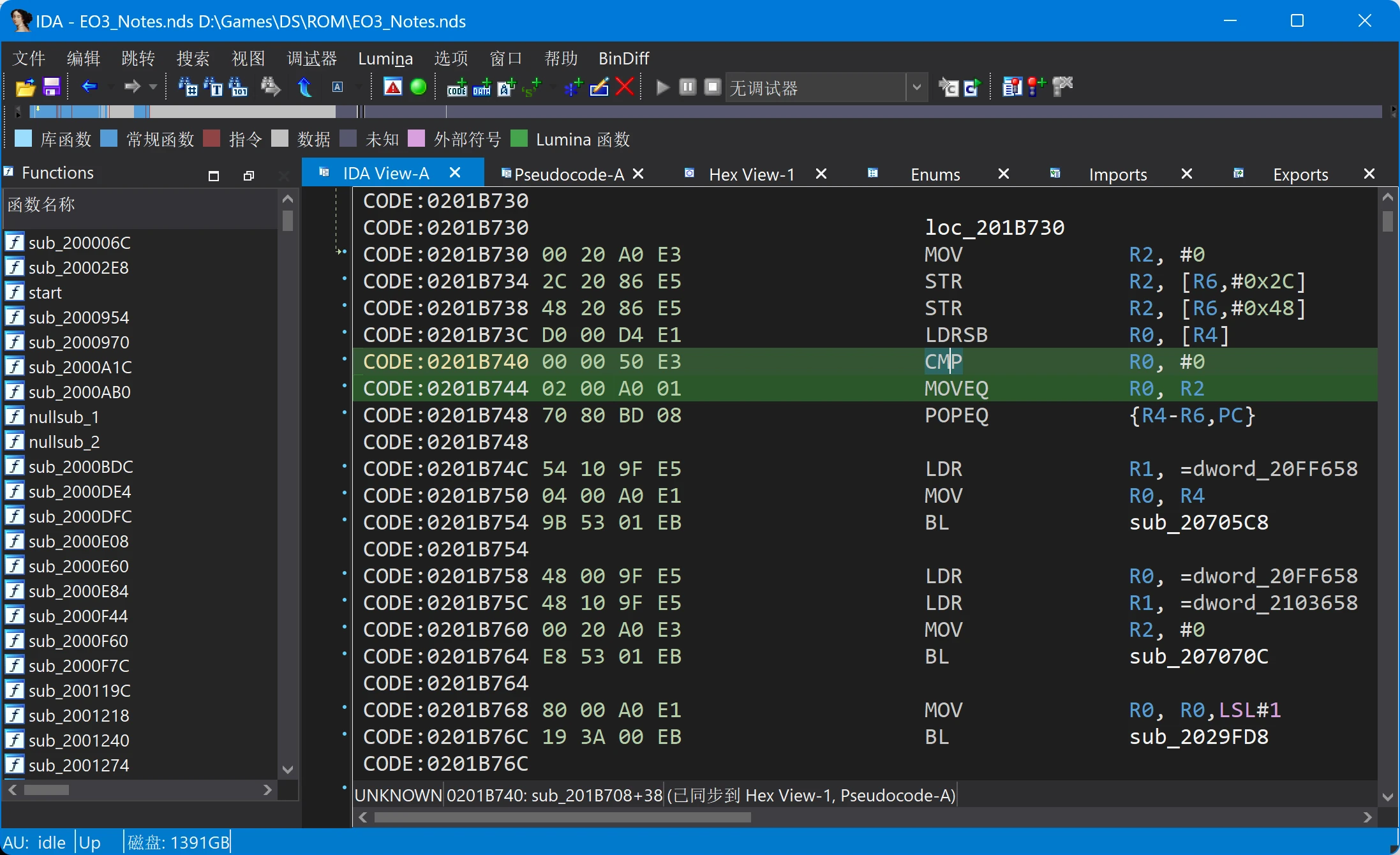 IDA Pro反汇编代码
IDA Pro反汇编代码
注意到这附近有几个函数,跳转过去搜索一下。如果你注意力惊人的话,可以发现sub_201B1A4()这个函数:
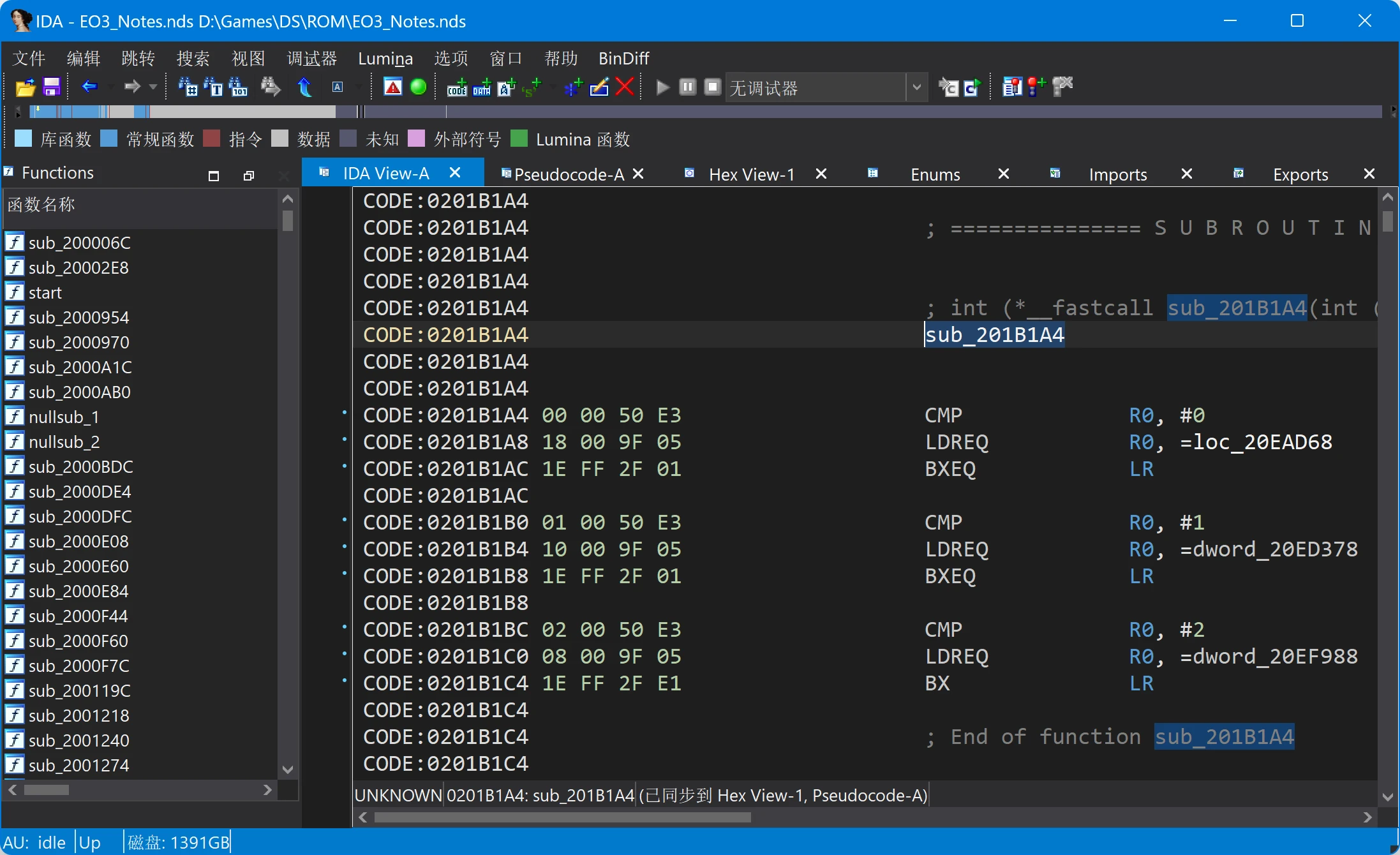 sub_201B1A4函数
sub_201B1A4函数
这个函数比较了R0寄存器和0、1、2是否相等,如果相等则返回不同的偏移量。那么这些偏移量跳转到哪里呢?
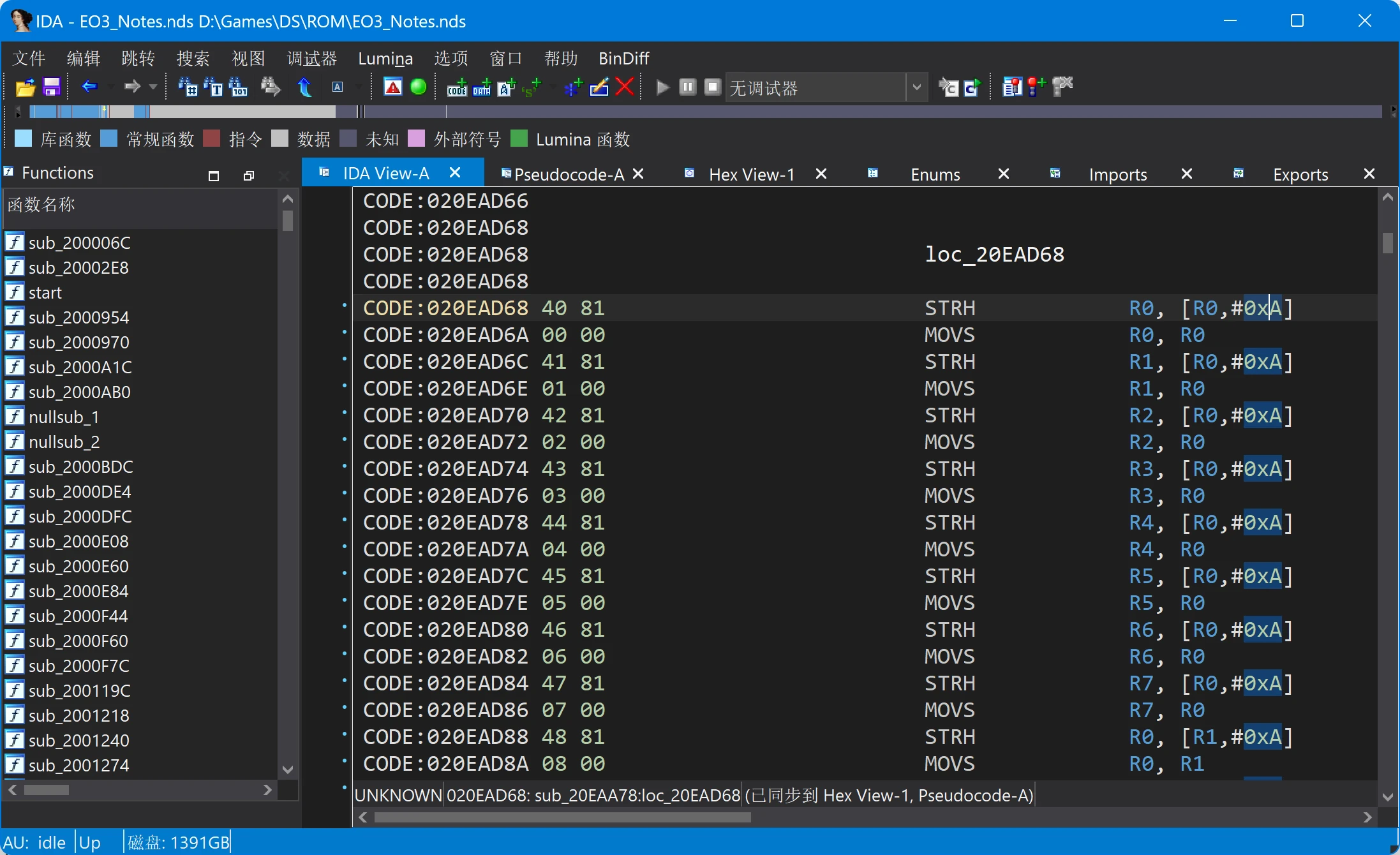 loc_20EAD68处的数据
loc_20EAD68处的数据
IDA Pro将这些数据识别成了指令,但是如果熟悉Shift-JIS编码的话,可以知道81 40恰好对应Shift-JIS编码的 字符,而下面的00 00可以视为编号。继续向下看,可以看出来每4个字节对应一个字符,前两个字节是用小端序编码的Shift-JIS编码,后两个字节是编号。怪不得我在arm9.bin里找不到这个映射表,原来是用小端序存储的。正常情况下,Shift-JIS编码都是大端序,也就是高位字节在前,低位字节在后,这样可以用高字节区分字符数据的长度是1个字节还是2个字节。而数值型数据一般都是小端序,也就是低位字节在前,高位字节在后,这样可以直接用数值大小来比较。
既然找到了对应关系,那么接下来就是想办法手动生成一个映射表了。需要注意的是,由于汉化所需要的中文字符一般都远多于原来的字符,所以映射表的长度也比原来大,直接写入原来的位置会覆盖掉后面的数据。好在游戏里保存了3份映射表,分别对应不同的字号,因此可以直接让3个字体共用一个映射表,然后把映射表的偏移量数据都改成一样的。
知道了文本的编码方式、字库格式、文本与字库的映射关系,是不是就万事大吉了呢?并不是,因为如果把至今为止的结果导入到游戏中,会显示成这样:
 初步尝试之后的结果
初步尝试之后的结果
可以看出来有明显的缺字问题。究竟是哪里有问题呢?
逆向第二步:寻找缺字原因
既然已经知道函数sub_201B1A4()是用来载入映射表的,那么就检查一下它的调用情况吧。这个函数有3处调用:
复制代码- sub_201B2F0+14
- sub_201B3E0+14
- sub_201B4C8+2C
其中第二处sub_201B3E0+14就是上一步中调用它的位置。跳转到第一处调用,可以看到附近还调用了另一个函数sub_201B1D4():
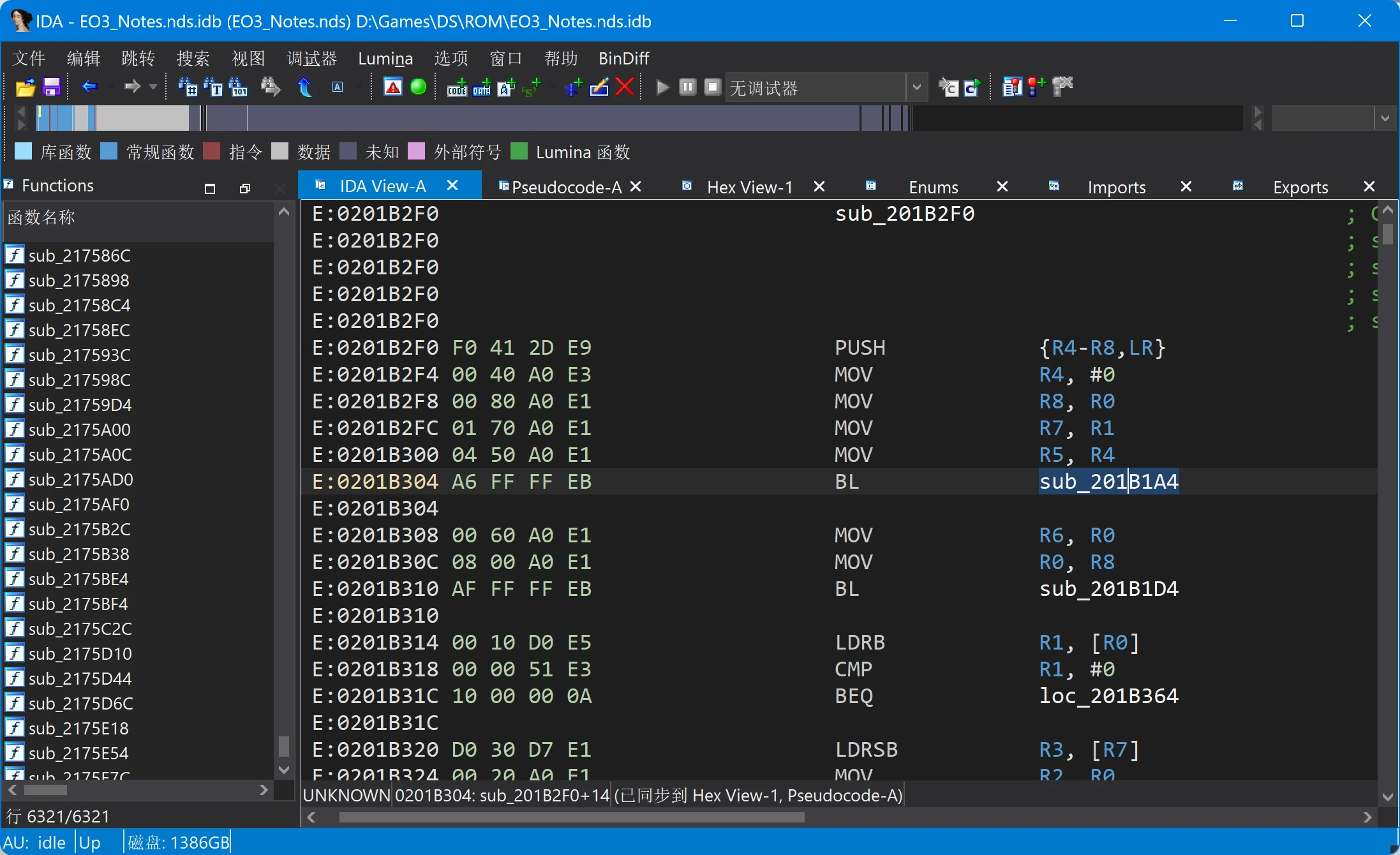 sub_201B2F0+14处的反汇编代码
sub_201B2F0+14处的反汇编代码
跳转过去看看:
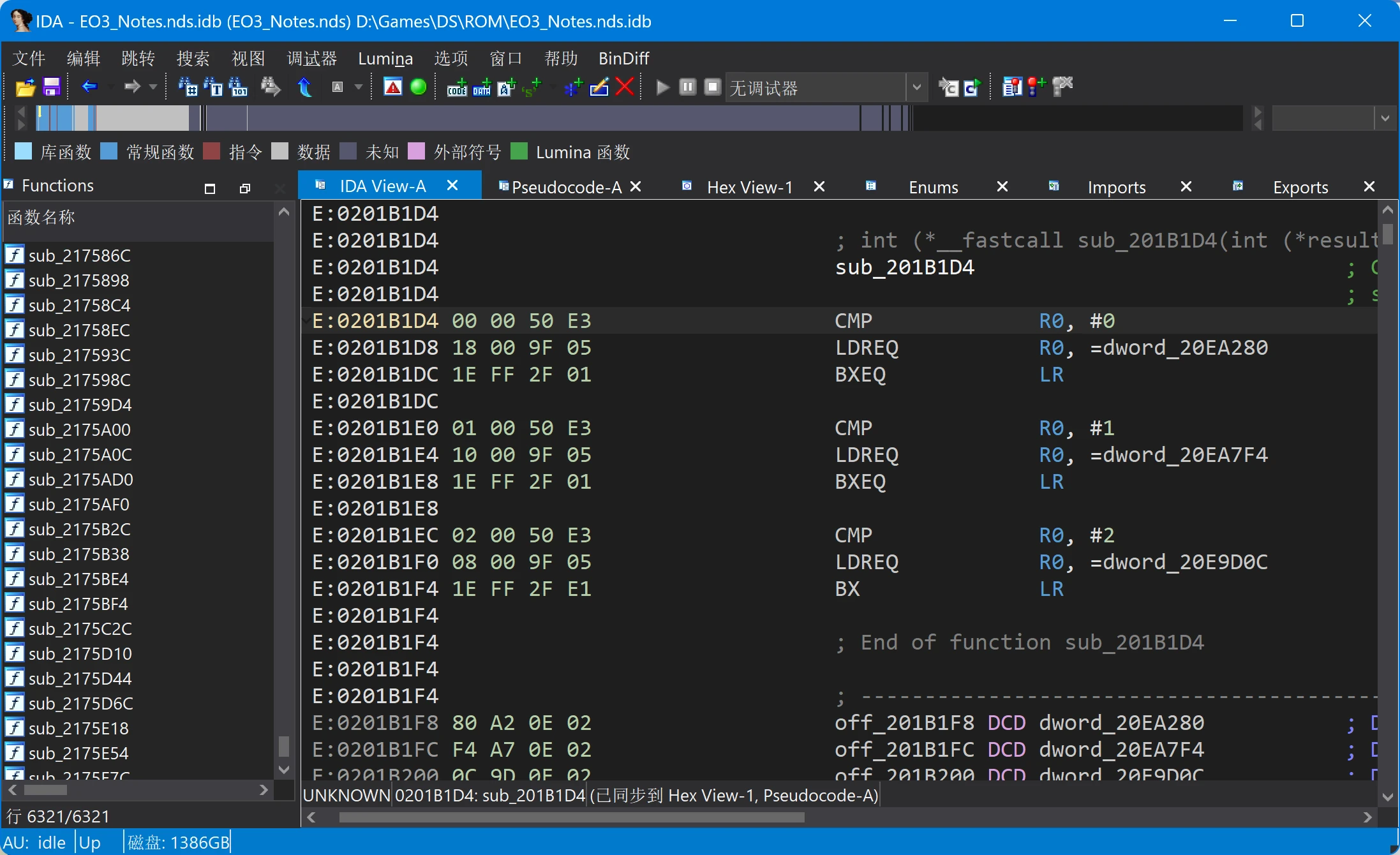 sub_201B1D4函数
sub_201B1D4函数
好熟悉的结构,和上面的映射表如出一辙。跳转到dword_20EA280对应的数据:
复制代码- Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
- 000EA280 81 00 83 09 83 09 83 09 83 09 00 00 10 00 20 00 ..ƒ.ƒ.ƒ.ƒ..... .
- 000EA290 30 00 3F 00 4F 00 5F 00 6C 00 74 00 7B 00 81 00 0.?.O._.l.t.{...
- 000EA2A0 8A 00 82 00 83 09 83 09 83 09 83 09 93 00 94 00 Š.‚.ƒ.ƒ.ƒ.ƒ.“.”.
- 000EA2B0 9D 00 AD 00 B7 00 C6 00 D2 00 E2 00 F2 00 02 01 ....·.Æ.Ò.â.ò...
- 000EA2C0 12 01 22 01 83 00 83 09 83 09 83 09 83 09 24 01 ..".ƒ.ƒ.ƒ.ƒ.ƒ.$.
- 000EA2D0 34 01 44 01 54 01 63 01 73 01 7B 01 8B 01 93 01 4.D.T.c.s.{.‹.“.
- 000EA2E0 A3 01 83 09 83 09 84 00 83 09 83 09 83 09 83 09 £.ƒ.ƒ.„.ƒ.ƒ.ƒ.ƒ.
- 000EA2F0 AA 01 BA 01 CA 01 CB 01 DA 01 EA 01 ED 01 FD 01 ª.º.Ê.Ë.Ú.ê.í.ý.
- 000EA300 83 09 83 09 83 09 83 09 87 00 83 09 83 09 83 09 ƒ.ƒ.ƒ.ƒ.‡.ƒ.ƒ.ƒ.
- 000EA310 83 09 0C 02 1C 02 2B 02 3B 02 42 02 52 02 83 09 ƒ.....+.;.B.R.ƒ.
- 000EA320 83 09 83 09 83 09 83 09 83 09 88 00 83 09 83 09 ƒ.ƒ.ƒ.ƒ.ƒ.ˆ.ƒ.ƒ.
- 000EA330 83 09 83 09 83 09 83 09 83 09 83 09 83 09 56 02 ƒ.ƒ.ƒ.ƒ.ƒ.ƒ.ƒ.V.
- 000EA340 57 02 5C 02 60 02 6A 02 74 02 7F 02 89 00 83 09 W.\.`.j.t...‰.ƒ.
- 000EA350 83 09 83 09 83 09 84 02 8C 02 93 02 9A 02 A4 02 ƒ.ƒ.ƒ.„.Œ.“.š.¤.
- 000EA360 AF 02 B7 02 BE 02 CB 02 D4 02 DF 02 E5 02 8A 00 ¯.·.¾.Ë.Ô.ß.å.Š.
- 000EA370 83 09 83 09 83 09 83 09 EE 02 FA 02 03 03 0D 03 ƒ.ƒ.ƒ.ƒ.î.ú.....
看着很乱,但是还是能看出来一定的规律的。首先,数据中有很多83 09,即小端序存储的0x983 = 2435。恰好第一个字库的字符数也是2435。对于第二个字库对应的数据也有类似的情况,说明应该不是巧合。其次,如果不看83 09,剩余的数据按两个字节一组(即short类型)来看,基本符合递增的趋势,只有几处例外,比如0x20EA280(内存地址,下同)处的81 00、0x20EA2A2处的82 00、0x20EA2C4处的83 00等。恰好这几处例外的位置相差0x22,显然,例外数据应该是某种标识符,剩下0x20字节则是10组short类型数据。而这些标识符依次是0x81、0x82、0x83,恰好是Shift-JIS双字节编码的第一个字节。因此可以推断,这些数据应该是用来标识字库中的字符的。那么这10组short类型的数据是什么呢?如果把0x983看作是缺失数据的默认值,那么其余的数据应该是用来标识字符在映射表中的编号的。尝试解读一下:
| 标识符 |
数据序号 |
数据值 |
映射表中对应字符 |
字符编码 |
| 0x81 |
0x04 |
0x0000 |
(全角空格) |
0x8140 |
| 0x81 |
0x05 |
0x0010 |
 ̄ |
0x8150 |
| 0x81 |
0x06 |
0x0020 |
~ |
0x8160 |
| 0x81 |
0x07 |
0x0030 |
} |
0x8170 |
| 0x81 |
0x08 |
0x003f |
÷ |
0x8180 |
| 0x81 |
0x09 |
0x004f |
$ |
0x8190 |
| 0x81 |
0x0a |
0x005f |
□ |
0x81a0 |
| 0x81 |
0x0b |
0x006c |
∈ |
0x81b8 |
| 0x81 |
0x0c |
0x0074 |
∧ |
0x81c8 |
| 0x81 |
0x0d |
0x007b |
∠ |
0x81da |
| 0x81 |
0x0e |
0x0081 |
≒ |
0x81e0 |
| 0x81 |
0x0f |
0x008a |
Å |
0x81f0 |
这下就清晰很多了,标识符是高字节,其后的数据是0x10区间内首个字符的编号。如果某个区间内没有字符,那么就用映射表的长度来填充。这样可以大幅度缩短查找时的速度,只需要先查找到该区间内首个字符,然后再向后查找,就可以通过较少次数的比较迅速找到字符对应的编码。改一下名字,然后反编译:
复制代码- int __fastcall sub_201B2F0(int font_index, shift_jis_char *text)
- {
- int v2; // r4
- int low_byte_00; // r5
- char_list_item *char_list_offset; // r6
- fast_index_item *fast_index_offset; // r0
- fast_index_item *v8; // r2
- int high_byte_low; // t1
- int char_code; // r2
- v2 = 0;
- low_byte_00 = 0;
- char_list_offset = get_char_list_offset(font_index);
- fast_index_offset = get_fast_index_offset(font_index);
- if ( LOBYTE(fast_index_offset->high_byte) )
- {
- v8 = fast_index_offset;
- while ( text->hi != SLOBYTE(v8->high_byte) )
- {
- high_byte_low = LOBYTE(v8[1].high_byte);
- ++v8;
- ++v2;
- if ( !high_byte_low )
- goto LABEL_6;
- }
- low_byte_00 = *(__int16 *)((char *)&fast_index_offset[v2].low_byte_00 + ((2 * (text->lo >> 4)) & 0x1F));
- }
- LABEL_6:
- if ( !LOBYTE(fast_index_offset[v2].high_byte) )
- low_byte_00 = (__int16)fast_index_offset[v2].low_byte_00;
- char_code = char_list_offset[low_byte_00].char_code;
- if ( !char_list_offset[low_byte_00].char_code )
- return end_201B3DC;
- while ( (unsigned __int16)((text->hi << 8) + (unsigned __int8)text->lo) != char_code )
- {
- char_code = char_list_offset[++low_byte_00].char_code;
- if ( !char_list_offset[low_byte_00].char_code )
- return end_201B3DC;
- }
- return (unsigned __int16)(low_byte_00 + 1);
- }
再看sub_201B4C8+2C处的调用,发现了另一个函数sub_201B204():
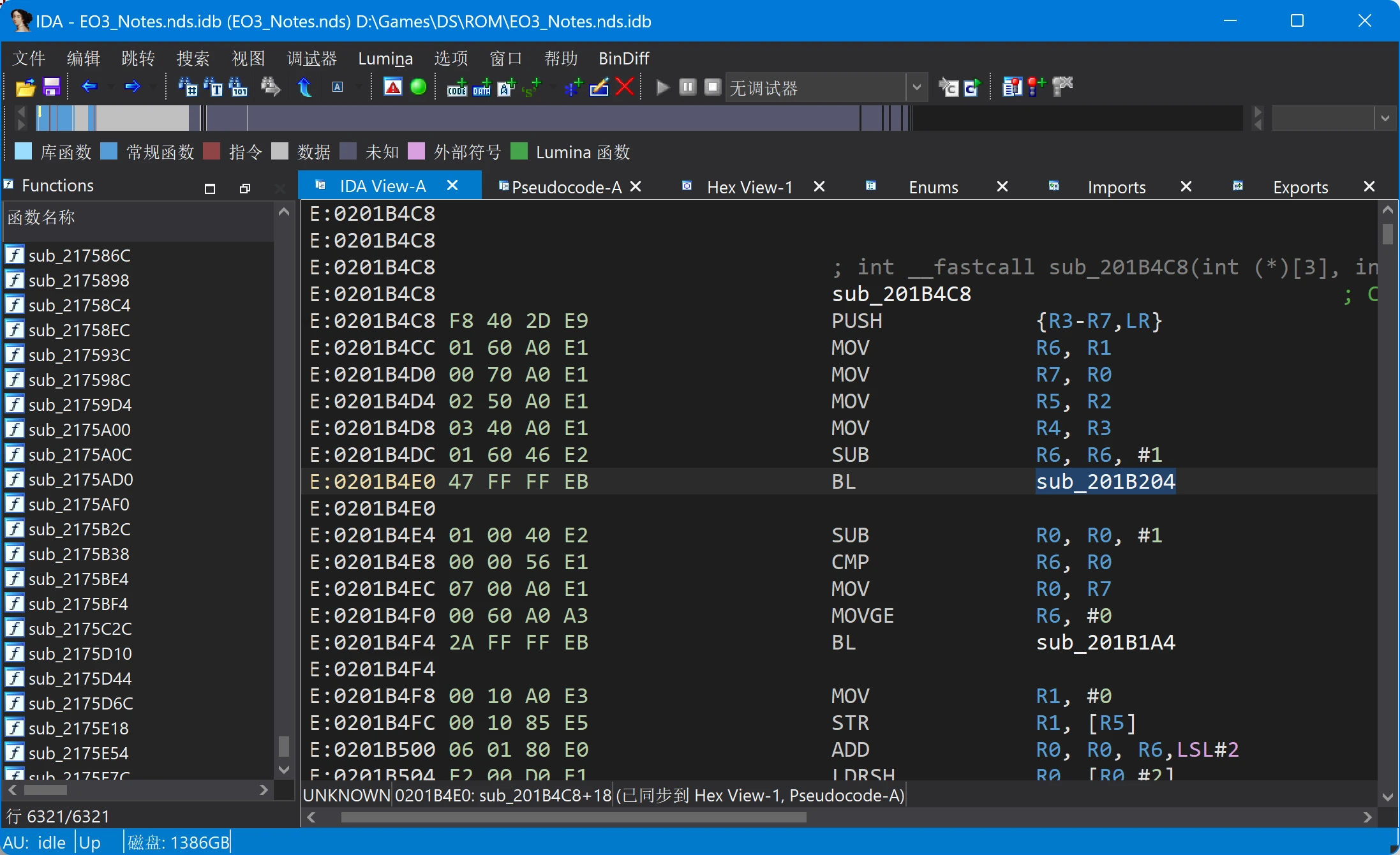 sub_201B4C8+2C处的反汇编代码
sub_201B4C8+2C处的反汇编代码
跳转过去看看:
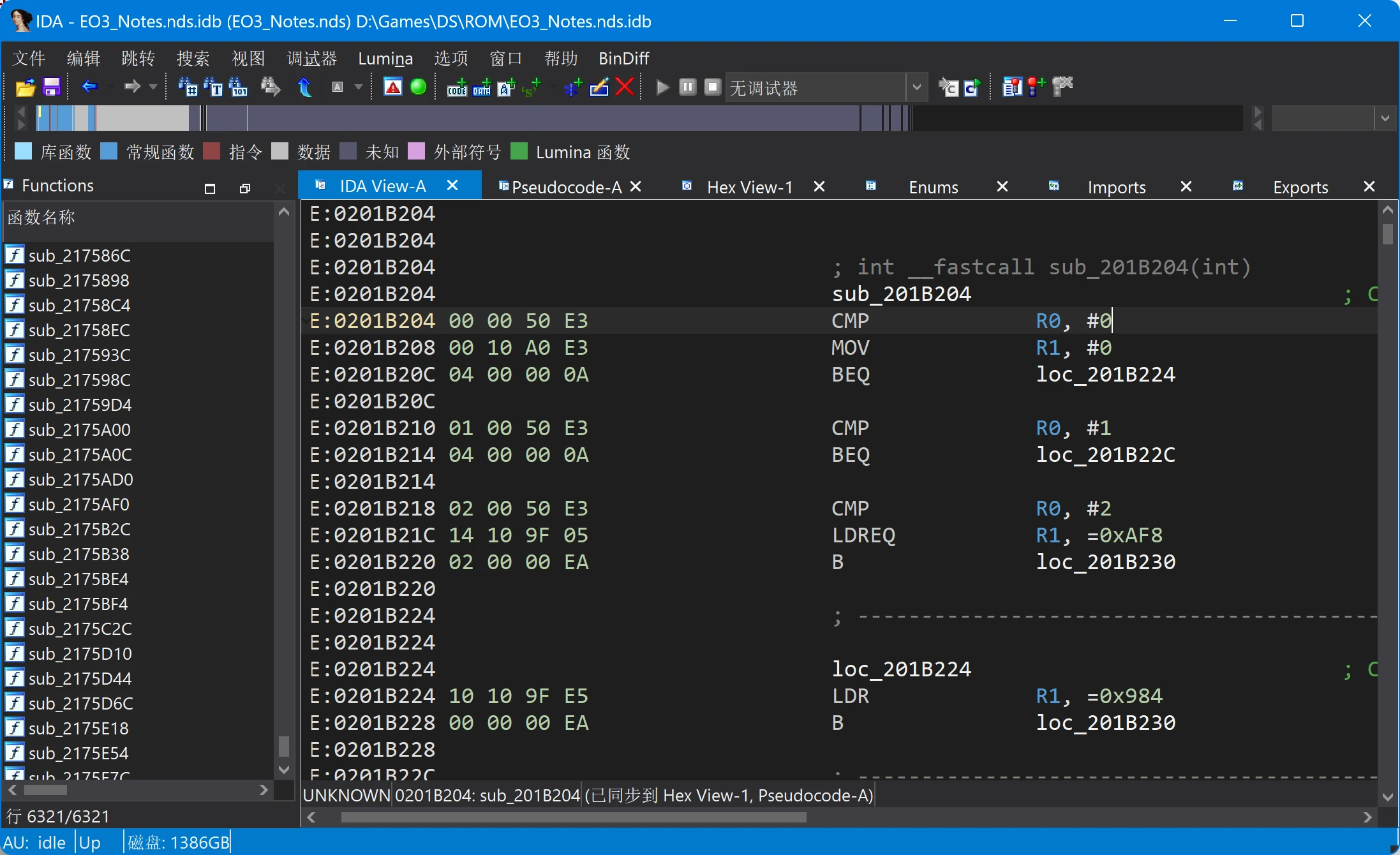 sub_201B204函数
sub_201B204函数
显然这里存储了字库的长度,调用处的反编译代码:
复制代码- int __fastcall convert_index_to_offset(int font_index, int char_index, _DWORD *a3, _DWORD *a4)
- {
- int v7; // r6
- char_list_item *char_list_offset; // r0
- int result; // r0
- v7 = char_index - 1;
- if ( char_index - 1 >= get_char_count(font_index) - 1 )
- v7 = 0;
- char_list_offset = get_char_list_offset(font_index);
- *a3 = 0;
- result = (__int16)char_list_offset[v7].char_index;
- *a4 = result;
- return result;
- }
因此,对映射表的处理还需要额外加上这两处逻辑。
结束了吗?
 继续尝试之后的结果
继续尝试之后的结果
处理好映射表之后,总算是不缺字了。但是还有一个问题:游戏开始时的文本没有居中对齐,显得很难看。显然,游戏存储的位置是文本最左侧的位置,而当文本长度变化后,就会显得没有居中。关于这个问题的处理,且听下回分解。