最近我对游戏汉化热情高涨,正好凉宫春日相关的游戏有几部作品至今没有汉化,其中就包括了世嘉发行的两部作品《凉宫春日的串联》《并联》(日文汉字写作为“直列”“并列”)。之前有一位前辈写过一篇“NDS《凉宫春日的直列》的一些破解信息”,但是由于年代久远,CSDN开始收费了,这篇文章的全文也没法看了。
不过,我在英文网站上找到了Haroohie Translation Club制作的英文化补丁,并且构建代码是开源的。我拉取到本地试了一下,代码功能很完善,完全可以直接拿过来制作汉化补丁。当然,英文化和中文化的工作重心还是有一定区别的,不能直接照搬,但是前辈们取得的经验还是值得借鉴和学习的。本着互相交流的精神,我就把我的研究成果写出来和大家分享。
导入导出工具
Haroohie Translation Club制作的导入导出工具ChokuretsuTranslationUtility的功能已经相当完善了,不过文本的导入导出格式是.resx格式,我用着不太习惯,所以我添加了导入/导出为.json格式的功能。修改后的代码可以参见此处。
除了导入导出文本外,这个工具还支持导入和导出图片,可以直接用。
字库
先简单介绍一下这个游戏ROM的文件结构:
复制代码- ├── dat.bin
- ├── evt.bin
- ├── grp.bin
- ├── scn.bin
- ├── snd.bin
- ├── bgm
- │ ├── BGM001.bin
- │ ├── BGM002.bin
- │ ├── ...
- │ └── BGM034.bin
- ├── movie
- │ ├── MOVIE00.mods
- │ └── MOVIE01.mods
- └── vce
- ├── ANZ_ANOTHER00.bin
- ├── ANZ_ANOTHER01.bin
- ├── ...
- └── TRY_WRITE00.bin
从文件名可以大概看出,dat.bin存放数据文件,evt.bin存放游戏剧情相关的脚本,grp.bin存放图片文件,这三个文件实际上都是一个文件包,其中储存了较多的小文件。其他文件和音频或视频相关。要修改的字库包括了码表和图片,码表是dat.bin中的第0x71个文件,图片是grp.bin中的第0xE50个文件。
码表
用ChokuretsuTranslationUtility中的命令行工具“ChokuretsuTranslationCLI”提取码表文件,用HxD打开:
复制代码- Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
- 00000000 01 00 00 00 38 11 00 00 14 00 00 00 14 00 00 00 ....8...........
- 00000010 01 00 00 00 81 97 81 41 81 42 81 44 81 45 81 46 .....—.A.B.D.E.F
- 00000020 81 48 81 49 81 51 81 58 81 5B 81 5C 81 60 81 63 .H.I.Q.X.[.\.`.c
- 00000030 81 65 81 66 81 67 81 68 81 69 81 6A 81 73 81 74 .e.f.g.h.i.j.s.t
- 00000040 81 75 81 76 81 77 81 78 81 79 81 7A 81 7B 81 7C .u.v.w.x.y.z.{.|
前0x14个字节显然是文件头,其中0x04-0x07是文件的大小(后续扩充码表需要修改此处)。从0x14到最后是字体图片包含的所有字符,按顺序排列。这种双字节的字符首先考虑UTF-16-LE编码,但是发现是乱码,于是尝试了一下Shift-JIS编码,发现和提取出来的图片是一致的。直接拿VS Code打开,改一下编码,就能得到包含的字符:
复制代码- @、。.・:?!_々ー―~…‘’“”()《》「」『』【】+-×=°%&☆■♪0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzぁあぃい...
因为导入的文本是简体中文,所以需要想办法把简体中文汉字对应到Shift-JIS编码中。我本来想直接拿GB18030编码直接扔进去,但是发现GB18030包含的中文汉字远多于Shift-JIS包含的日文汉字,因此作罢。最后的解决方案是,统计翻译后的文本中出现的简体中文汉字次数,按照使用次数从多到少排序,然后依次检查是否在原有的码表中。如果在,就直接用原有的Shift-JIS编码;如果不在,就用未在翻译后的文本中出现的日文汉字替换掉。这样就能保证尽可能多的字符能够正确显示。最后将替换的对应表保存成.json文件,供导入文本时使用。
码表的处理思路与英文化项目类似,不过中文化需要用到的汉字远远多于英文化。我提取出了全部文本并且用机翻测试了一下,需要用到的汉字大概有3000字,而原有的码表只包含了约2200字。解决方法要么是精简用字,要么对码表扩容。(顺带一提,这个游戏全部文本大概80万字,其中包含了很多分支,所以如果只是想通关的话很简单,五章就结束了,但是要看完全部分支的话就需要很长时间了。当然,对于翻译来说也是个地狱,就连机翻我都用了3天才处理完。)
字体图片
有了码表和对应表,生成图片就简单了很多。字体大小是14px,这个大小正好适合中文像素字体(可以参考星夜之幻前辈写的文章“小点阵字体速览”)。我用的是Windows自带的宋体,实际生成是13x14px的字符。自动构建的时候也可以读取C:/Windows/Fonts/simsun.ttc。
不过这里有一个小小的问题,由于游戏中文字的行高正好就是14px,如果用14px的字体就会出现上下两行的文字有粘连。这个问题就需要通过修改游戏的可执行文件来解决了。
另外,同样是基于前文所说的码表包含字符不够多的原因,生成的字体图片也需要比原来的图片更大。原来的图片尺寸是16x35328的,如果直接用ChokuretsuTranslationCLI导入,将会只导入图片的前面一部分。在不修改代码的前提下,解决办法是先手动生成一个空的二进制文件导入进去,然后再导入图片,此时ChokuretsuTranslationCLI就会以新的尺寸处理图片。
图片
图片的修改没什么好说的,就是简单地导出、修改、导入。只不过有些图片导出后的图块排序和实际显示的图块排序有些差异,需要手动处理一下,也比较简单,不再赘述了。
可执行文件
在我深入研究之前,我对NDS游戏的可执行文件的了解不多。不过随着我深入研究了这个游戏以及《宝可梦》第四世代的汉化修正项目,至少也算是歪打正着地解决了我遇到的问题。
首先大致说明一下NDS游戏的可执行文件。其分为arm9和arm7两部分,而这两部分又分为主程序(arm9.bin/arm7.bin)和补丁程序(overlay9_xxxx.bin/overlay7_xxxx.bin)。以arm9为例,arm9.bin中保存了程序的通用部分,会在游戏启动时加载到主内存(起始点为0x02000000);而overlay9_xxxx.bin则根据需要动态加载到内存中。所有的二进制文件都是ARM的机器码,所以要想修改游戏的逻辑,就需要对机器码进行修改。这里就需要用到反汇编工具了。
参考了Haroohie Translation Club写的文章“Chokuretsu ROM Hacking Challenges Part 2 – Archive Archaeology”,可以使用IDA搭配插件对NDS的ROM文件进行反汇编。(顺带一提,原作者仅实现了反汇编arm9.bin的功能,没有实现overlay9_xxxx.bin的功能,我在原作者的基础上添加了overlay9_xxxx.bin的反汇编功能,参见此处。arm7的反汇编没有做,目前也没什么需求,如果有需求再说。)
字体行高
在Haroohie Translation Club的构建项目“ChokuretsuTranslationBuild”中我发现src/symbols.x文件有一些该团队已经命名的函数:
复制代码- MI_DmaCopy32 = 0x02006ED0;
- MIi_CpuClearFast = 0x0200738C;
- GX_SetBankForBG = 0x0200277C;
- GX_SetGraphicsMode = 0x020025B8;
- arc_loadFileAndResolvePointers = 0x02033FC4;
- scene_renderDialogue = 0x0202D41C;
其中scene_renderDialogue这个函数看着很有用,拿IDA看一眼:
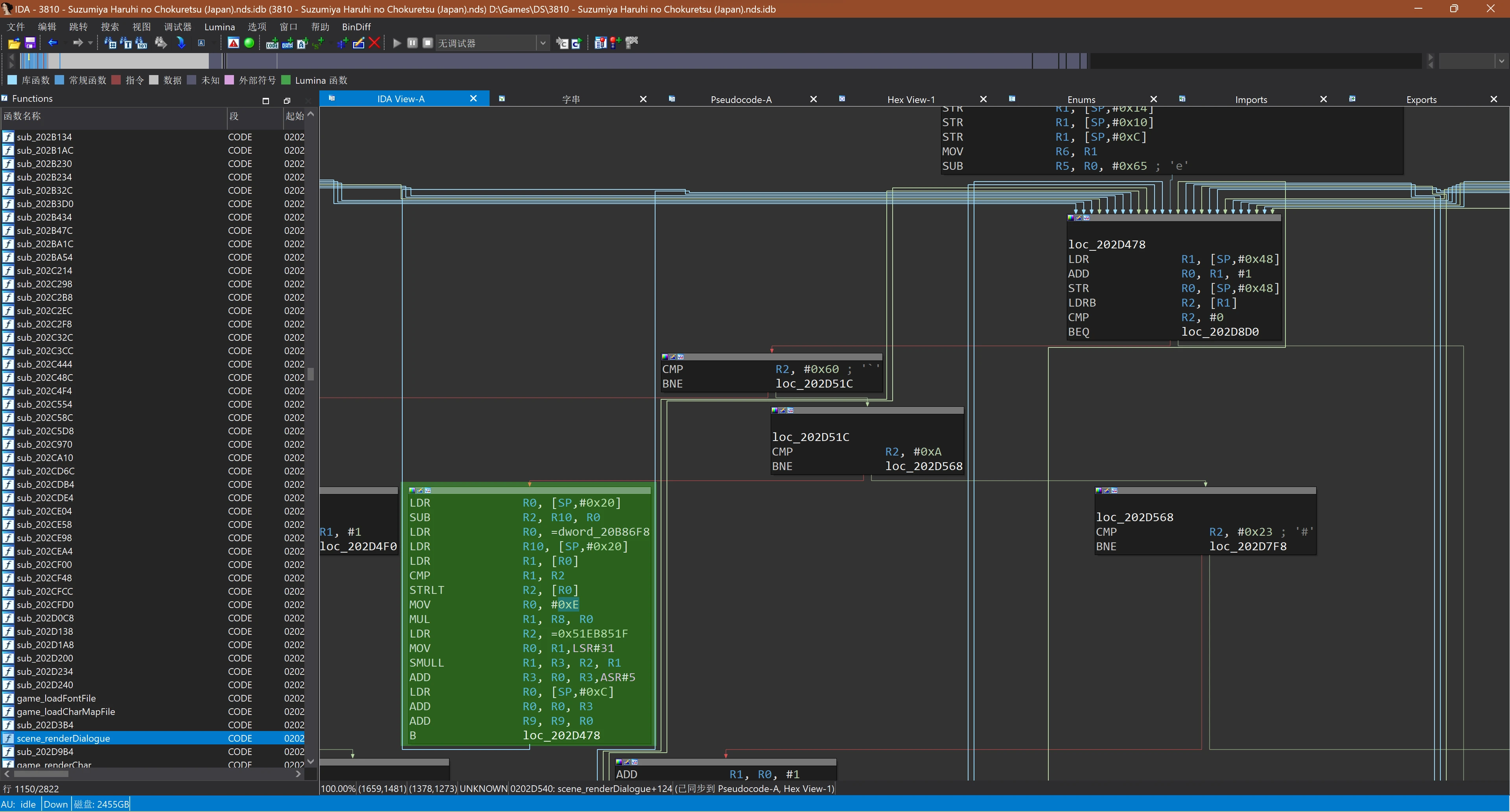 使用IDA反汇编结果,其中与行高相关的内容已经高亮为了绿色
使用IDA反汇编结果,其中与行高相关的内容已经高亮为了绿色
这里大概能看出来cmp r2, #0、cmp r2, #0x60、cmp r2, #0xa、cmp r2, #0x23是在比较,正好U+000A是换行符,而对应的分支里面有个mov r0, #0x0e。0x0e刚好又是十进制的14,前面说过游戏中文字的行高是14,这不是正好对上了吗?修改一下,改成0x10(十进制的16),回到游戏里一看,没错!就这样歪打正着地解决了。
 修改行高为16px的结果
修改行高为16px的结果
字库扩容
这个问题困扰了我挺久,单纯修改码表大小没用,必须得同时修改图片大小才能让游戏中正常显示。但是,如果让图片包含大约2500个汉字(仅扩容300字),导入到游戏里就会出错,具体表现为游戏在厂商图标显示完毕后白屏。这显然应该是图片太大导致内存不够用了,但我一开始没有想到较好的解决办法。尽管我在字库图片读取、文本显示等多个地方都打了断点,但是还是没琢磨清楚该怎么改。
这个时候我碰巧又看了Haroohie Translation Club的构建项目,发现了一个提交:
复制代码- commit f8884a8057f38a9f6b0f384acf7bf3f95541a096
- Author: jonko0493 <email>
- Date: Tue Oct 10 03:51:20 2023 -0700
- Print debug logs to no$ console
拉下来在本地构建一下,把可执行文件相关的修改导入进去,然后拿DeSmuME打开ROM文件:
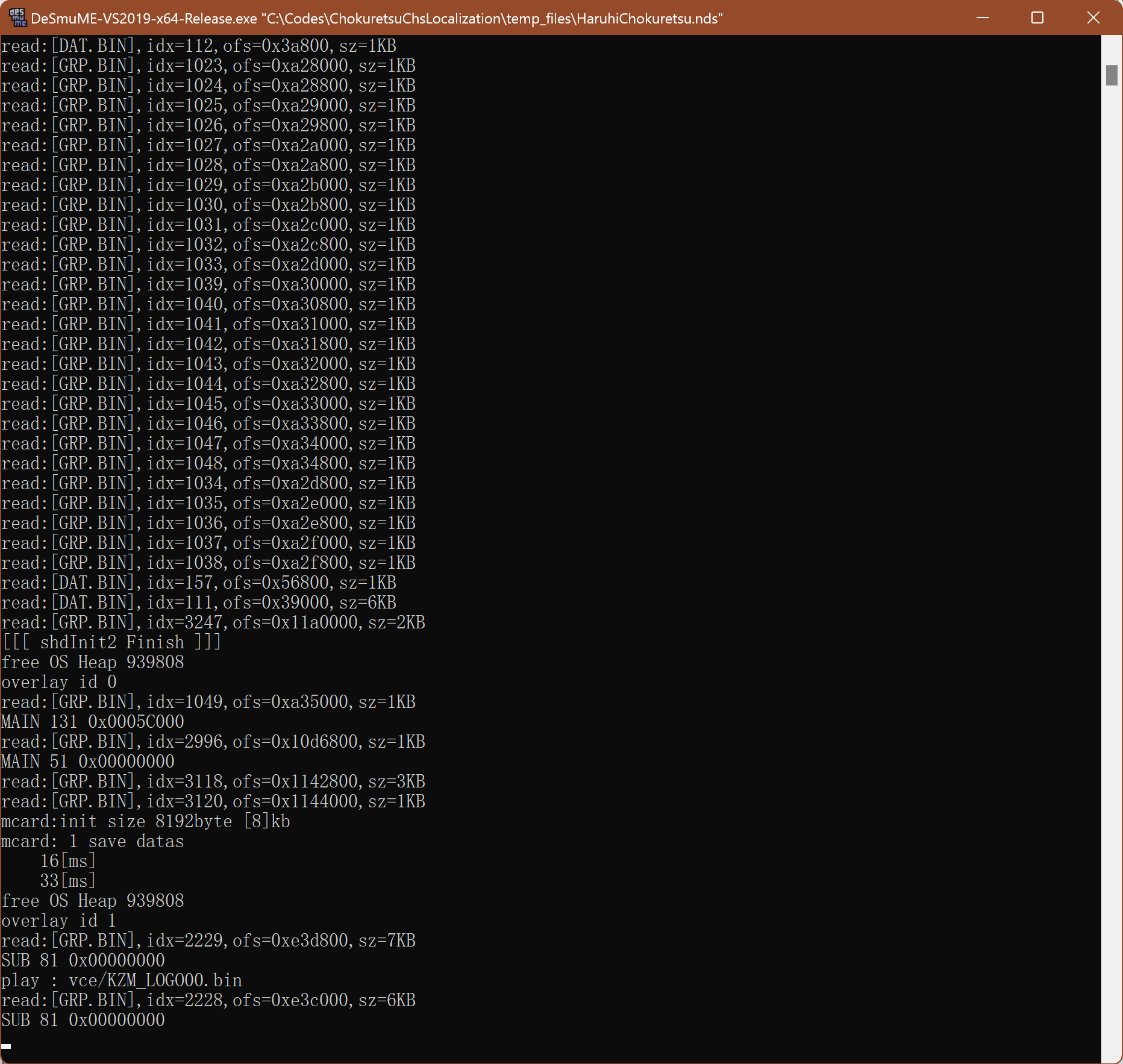 DeSmuME的控制台,展示了调试信息
DeSmuME的控制台,展示了调试信息
好家伙,真的把日志输出到模拟器的控制台里了。这下就好办了,生成一个超级大的图片,导入到游戏里,发现报错内存不够了:
复制代码- memory is not enough[32256Byte]
- --memory report start--
- --use
- list: 0 addr:021A2230 size: 16
- list: 1 addr:021A2240 size: 32
- list: 2 addr:021A2260 size: 224
- ...
- list: 23 addr:02217CB0 size: 32256
- --free
- list: 24 addr:0221FAB0 size: 11152
- use memory size : 514176 503KB
- free memory size : 11152 11KB
- --memory report end--
计算了一下,内存分配的最终地址是0x0221FAB0 + 0x2B90 = 0x02222640(十进制的11152即为0x2B90),拿DeSmuME的内存工具设一下写入断点,发现写入的时候控制台的最后一行文本是这样的:
复制代码- gwork : s: 20e2660 e: 2242664: sz: 140000
拿IDA找这个字符串,然后跳转到调用的位置,发现了如下汇编代码:
复制代码- loc_202A980:
- LDR R1, =dword_20A9AC8
- MOV R0, #0x140000
- LDR R2, [R1,#8]
- ORR R2, R2, #1
- STR R2, [R1,#8]
- BL sub_2024750
- MOV R1, R0
- LDR R4, =dword_20A9AAC
- LDR LR, =dword_20A9AB4
- LDR R12, =dword_20A9AB0
- LDR R0, =aGworkSXEXSzX ; "gwork : s: %x e: %x: sz: %x\n"
- ADD R2, R1, #0x140000
- MOV R3, #0x140000
- STR R1, [R4]
- STR R1, [LR]
- STR R1, [R12]
- BL dbg_print20228DC
第一个#0x140000应该是和内存分配有关的,后面两个#0x140000是和调试信息输出有关的。因为想要把字库容量扩容到3000字左右,计算了一下,将这几个数字改为#0x160000即可满足需求。
此外,在另一个地方也发现了这个#0x140000:
复制代码- sub_202E158:
- LDR R0, =dword_20A9AB0
- LDR R1, =dword_20C0D38
- LDR R3, [R0]
- LDR R2, =dword_20A9AC8
- ADD R12, R3, #0x1400
- LDR R3, [R1]
- STR R12, [R0]
- STR R12, [R2]
- STR R3, [R1,#4]
- MOV R12, #0
- STR R12, [R3,#0xC]
- LDR R3, [R1,#4]
- LDR R0, =dword_20A9AAC
- STR R12, [R3,#0x10]
- LDR R12, [R2]
- LDR R3, [R1,#4]
- STR R12, [R3,#4]
- LDR R0, [R0]
- LDR R2, [R2]
- ADD R3, R0, #0x140000
- LDR R0, [R1,#4]
- SUB R1, R3, R2
- STR R1, [R0,#8]
- POP {R3,PC}
也同样修改为#0x160000。
结语
总体来说,我的研究成果基本上都是基于前辈们已有的结果,几个问题的解决方式也算是歪打正着,不过也算是有所收获。后续的工作主要就是翻译了,不过,研究如何汉化可比翻译文本有意思多了。
汉化相关的构建脚本已在GitHub上开源。