Recently, my enthusiasm for localizing games into Chinese has been high. There are several Suzumiya Haruhi games that have not been translated into Chinese, including two works released by Sega, “Suzumiya Haruhi no Chokuretsu” (The Series of Haruhi Suzumiya) and “Heiretsu” (Parallel). A senior once wrote an article titled “NDS《凉宫春日的直列》的一些破解信息” (Some Hacking Information on NDS game “Suzumiya Haruhi no Chokuretsu”), but due to its age, CSDN has started charging fees, and the entire article cannot be read.
However, I found an English patch created by Haroohie Translation Club, and the build code is open source. I pulled it to my local disk and tried it out. The code is very functional and can be directly used to create Chinese patches. Of course, there is still a certain difference in the focus of work between English and Chinese localization, so it cannot be directly copied. However, the experience gained by the predecessors is still worth learning and borrowing from. In the spirit of mutual communication, I will write down my research results and share them with everyone.
The import and export tool, ChokuretsuTranslationUtility, created by Haroohie Translation Club, has quite complete functions. But the import and export format of texts is in the . resx format, which I am not familiar with, so I added the function of importing/exporting in the . json format. The modified code can be found in here.
In addition to importing and exporting texts, this tool also supports importing and exporting images, which can be used directly.
Font
First, let me briefly introduce the file structure of the game ROM:
复制代码- ├── dat.bin
- ├── evt.bin
- ├── grp.bin
- ├── scn.bin
- ├── snd.bin
- ├── bgm
- │ ├── BGM001.bin
- │ ├── BGM002.bin
- │ ├── ...
- │ └── BGM034.bin
- ├── movie
- │ ├── MOVIE00.mods
- │ └── MOVIE01.mods
- └── vce
- ├── ANZ_ANOTHER00.bin
- ├── ANZ_ANOTHER01.bin
- ├── ...
- └── TRY_WRITE00.bin
From the file name, it can be roughly seen that dat. bin stores data files, evt. bin stores game storyline related scripts, and grp. bin stores image files. These three files are actually archive files, which stores a large number of small files. Other files related to audios or videos. To modify the font used in this game, I need to edit the character table and the image of it. The character table is the 0x71st file in dat. bin, and the image is the 0xE50th file in grp. bin.
Character Table
I extracted the character table file using the command-line tool “ChokuretsuTranslationCLI” in the ChokuretsuTranslationUtility, and opened it with HxD:
复制代码- Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
- 00000000 01 00 00 00 38 11 00 00 14 00 00 00 14 00 00 00 ....8...........
- 00000010 01 00 00 00 81 97 81 41 81 42 81 44 81 45 81 46 .....—.A.B.D.E.F
- 00000020 81 48 81 49 81 51 81 58 81 5B 81 5C 81 60 81 63 .H.I.Q.X.[.\.`.c
- 00000030 81 65 81 66 81 67 81 68 81 69 81 6A 81 73 81 74 .e.f.g.h.i.j.s.t
- 00000040 81 75 81 76 81 77 81 78 81 79 81 7A 81 7B 81 7C .u.v.w.x.y.z.{.|
The first 0x14 bytes are obviously the file header, where 0x04-0x07 is the size of the file (these bytes need to be modified after expanding the character table). From 0x14 to the last is all the characters contained in the font image, in order. UTF-16-LE encoding was first considered for these 2-byte characters, but it was found to be garbled. So I tried Shift-JIS encoding and found that it was consistent with the extracted image. The I opened it with VS Code directly and change the encoding to Shift-JIS, and I got characters included in the file:
复制代码- @、。.・:?!_々ー―~…‘’“”()《》「」『』【】+-×=°%&☆■♪0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzぁあぃい...
Since the modified text is in Simplified Chinese, I need to find a way to map Simplified Chinese characters to Shift-JIS codes. I wanted to directly use the GB18030 encoding at first, but I found that GB18030 contained far more Chinese characters than Shift-JIS, so I gave up. The final solution is to count the number of Simplified Chinese characters in the translated text, sort them according to the number of use, and then check whether they are in the original character table in turn. If yes, the original Shift-JIS code is directly used; If not, replace it with Japanese Kanji that does not appear in the translated text. This ensures that as many characters as possible can be displayed correctly. Finally, the correspondence table was saved as a .json file for use when importing text.
The processing idea of the character table is similar to that of the English project, but Chinese localization needs to use far more characters than English. I extracted all the text and tested it with the machine translation. The required Chinese characters are about 3,000 words, while the original character table only contains about 2,200 words. The solution is either to simplify the use of words, or to expand the capacity of the character table. (By the way, the whole text of the game is about 800,000 words in Japanese, including many branches. So, if someone just wants to clear the game, it is very simple because there are only 5 chapters. But if one wants to play all the branches, it will take a long time. Of course, it is also a hell for translation, and it even took me 3 days to finish the machine translation.)
Font Image
With a character table and correspondence table, generating images becomes much simpler. The font size is 14px, which is exactly suitable for Chinese pixel fonts (you can refer to the article “小点阵字体速览” (Small Pixel Font Overview) written by a senior 星夜之幻 (Xingyezhihuan)). I used SimSun, which is bundled with Microsoft Windows, to generate 13x14px characters. As for creating an automatically building workflow, the file C:/Windows/Fonts/simsun.ttc can be used.
However, there is a small issue here. As the line height of the text in the game is exactly 14px, using a 14px font will cause the text on the top and bottom lines to stick together. This problem needs to be solved by modifying the executable file of the game.
Additionally, due to the insufficient number of characters in the original character table that I mentioned earlier, the generated font image also needs to be larger than the original image. The original image size was 16x35328. If the image is imported directly using ChokuretsuTranslationCLI, only the top part of the image will be imported. The solution, without modifying the code, is to manually generate an empty binary file. Import that empty binary file first, and then import the image. Then, ChokuretsuTranslationCLI will process the image with the new size.
Images
Modifying images is very easy, just simply exporting, editing, and importing them. However, there are some differences in the sorting of exported tiles compared to the actual displayed image, which require manual processing. The steps are relatively simple, so I won’t go into further detail.
Executable File
Before delving deeper, I had limited knowledge about the executable files of NDS games. However, as I delved deeper into this game and the Chinese localization revision project for the Pokémon Gen IV, at least it was able to solve the problems I encountered in a straightforward manner.
Firstly, I’ll briefly explain the executable files of the NDS game. They are divided into two parts: arm9 and arm7, which are further divided into the main program (arm9.bin/arm7.bin) and overlay programs (overlay9_xxxx.bin/overlay7_xxxx.bin). Taking arm9 as an example, the general part of the program is saved in arm9.bin, which will be loaded into the main memory at game startup (starting from 0x0200000000); And overlay9_xxxx. bin files are dynamically loaded into memory as needed. All binary files are ARM machine code, so if I want to modify the logic of the game, it is necessary to modify the machine code. This requires the use of disassembly tools.
Referring to the article written by Haroohie Translation Club – “Chokuretsu ROM Hacking Challenges Part 2 – Archive Archaeology”, IDA can be used with a plugin to disassemble NDS ROM files. (By the way, the original author only implemented the disassembly function of arm9. bin and did not implement the function of overay9_xxxx.bin. I added the disassembly function of ‘overay9_xxxx.bin` on the basis of the original author, see here. The disassembly function of arm7 was not done since there is currently no need for it. If there is a need, I will conduct further research.)
Font Line Height
In the build repository of Haroohie Translation Club, I found that the src/symbols.x file contains some functions that the team has already named:
复制代码- MI_DmaCopy32 = 0x02006ED0;
- MIi_CpuClearFast = 0x0200738C;
- GX_SetBankForBG = 0x0200277C;
- GX_SetGraphicsMode = 0x020025B8;
- arc_loadFileAndResolvePointers = 0x02033FC4;
- scene_renderDialogue = 0x0202D41C;
The function scene_renderDialogue looks very useful, take a look with IDA:
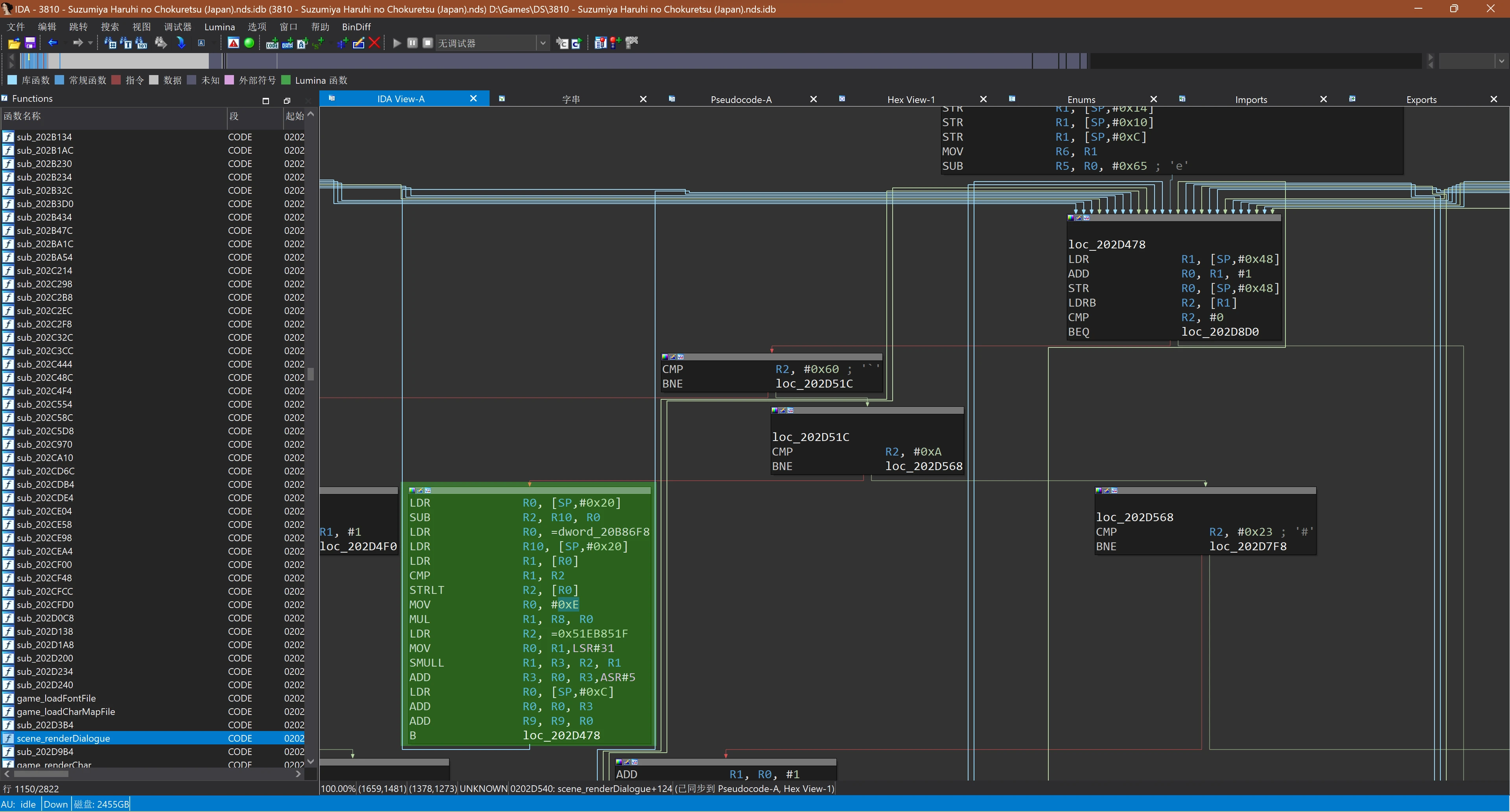 The result of disassembly using IDA, where the content related to line height were highlighted in green
The result of disassembly using IDA, where the content related to line height were highlighted in green
Here, we can roughly see that cmp r2, #0, cmp r2, #0x60, cmp r2, #0xa and cmp r2, #0x23 are comparing r2 with certain numbers. U+000A is a line break, and there is a statement mov r0, #0x0e in the corresponding branch. 0x0e is 14 in demical, and the line height of text in games is exactly 14 as I mentioned earlier. Then I modified it to 0x10 (16 in decimal), and went back to the game, perfect! So it was solved crookedly.
 The result of modifying line height to 16px
The result of modifying line height to 16px
Expanding the Character Table
This problem bothered me for quite a long time. Just changing the size of the character table has no use, and I have to modify the image size at the same time to make it display properly in the game. However, once the image contains approximately 2,500 Chinese characters (with only 300 characters expanded), importing it into the game will result in an error, which is manifested as a white screen after manufacturers’ logos are displayed. Obviously, this is due to the image being too large and causing insufficient memory, but I didn’t think of a better solution at first. Although I have made breakpoints in various places such as loading font image and displaying texts, I still haven’t figured out how to make the changes.
At this moment, I happened to look at the build repo of Haroohie Translation Club again and found a commit:
复制代码- commit f8884a8057f38a9f6b0f384acf7bf3f95541a096
- Author: jonko0493 <email>
- Date: Tue Oct 10 03:51:20 2023 -0700
- Print debug logs to no$ console
I pulled it down, built it locally, merged the modifications related to the executable file, and then opened the ROM file with DeSmuME:
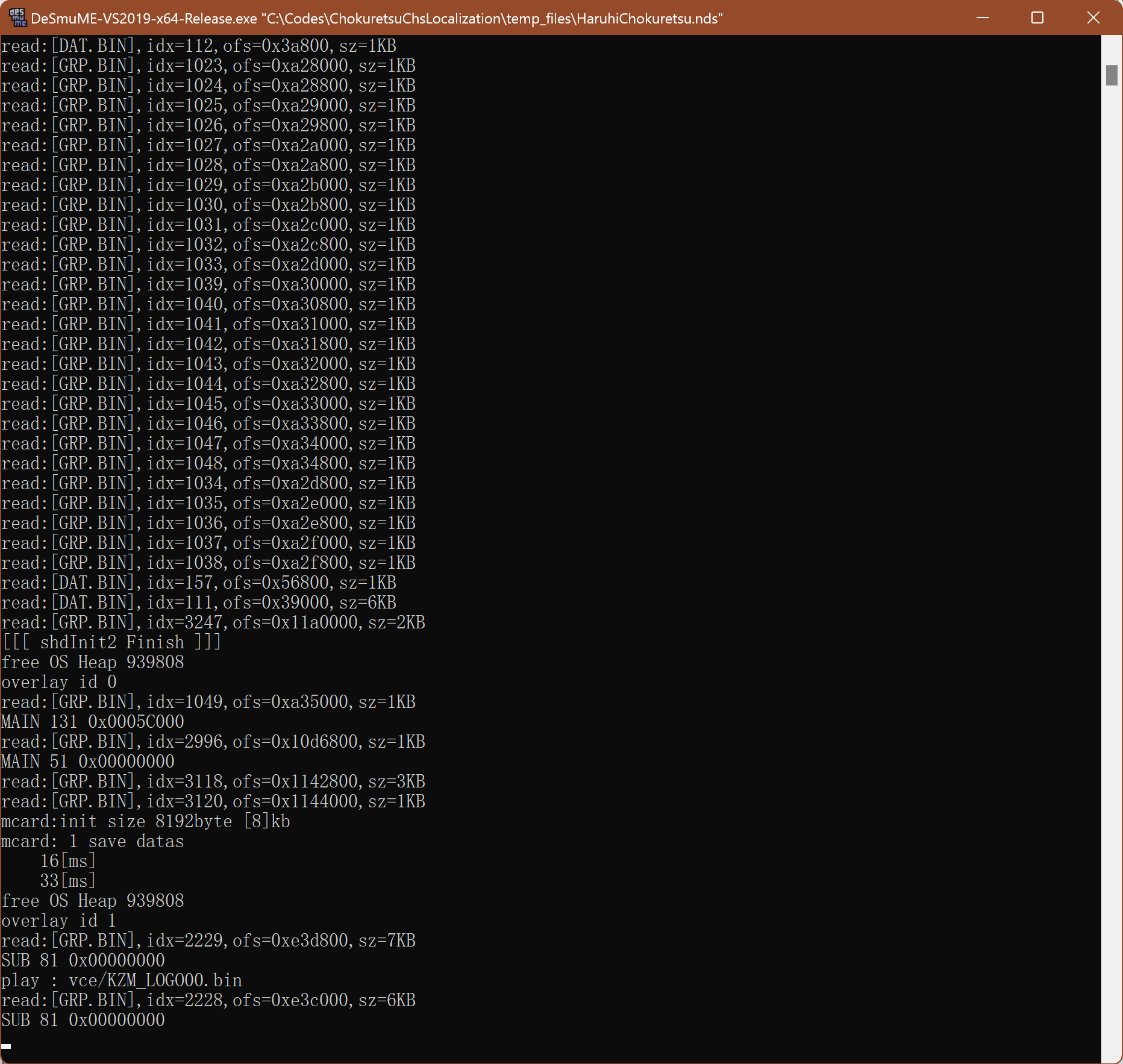 The console of DeSmuME, displaying debugging information
The console of DeSmuME, displaying debugging information
Wow, it really output the logs to the console of the emulator. Now it’s easy to handle. I generated a very large image, and imported it into the game. Then I found that there was an error message showing the memory was not enough:
复制代码- memory is not enough[32256Byte]
- --memory report start--
- --use
- list: 0 addr:021A2230 size: 16
- list: 1 addr:021A2240 size: 32
- list: 2 addr:021A2260 size: 224
- ...
- list: 23 addr:02217CB0 size: 32256
- --free
- list: 24 addr:0221FAB0 size: 11152
- use memory size : 514176 503KB
- free memory size : 11152 11KB
- --memory report end--
After my calculation, the final address for memory allocation is 0x0221FAB0 + 0x2B90 = 0x02222640 (11152 in decimal is 0x2B90). I used the memory tool of DeSmuME to set a write breakpoint, and the last line of texts in the console during the write operation is as follows:
复制代码- gwork : s: 20e2660 e: 2242664: sz: 140000
I used IDA to locate this string, then jumped to the calling location, and I found the following assembly codes:
复制代码- loc_202A980:
- LDR R1, =dword_20A9AC8
- MOV R0, #0x140000
- LDR R2, [R1,#8]
- ORR R2, R2, #1
- STR R2, [R1,#8]
- BL sub_2024750
- MOV R1, R0
- LDR R4, =dword_20A9AAC
- LDR LR, =dword_20A9AB4
- LDR R12, =dword_20A9AB0
- LDR R0, =aGworkSXEXSzX ; "gwork : s: %x e: %x: sz: %x\n"
- ADD R2, R1, #0x140000
- MOV R3, #0x140000
- STR R1, [R4]
- STR R1, [LR]
- STR R1, [R12]
- BL dbg_print20228DC
The first #0x140000 is likely related to memory allocation, while the latter two #0x140000 are associated with debug information output. Since I want to expand the character table capacity to around 3,000 characters, I calculated and changed these numbers to #0x160000 to meet the requirements.
In addition, I found this #0x140000 in another location as well:
复制代码- sub_202E158:
- LDR R0, =dword_20A9AB0
- LDR R1, =dword_20C0D38
- LDR R3, [R0]
- LDR R2, =dword_20A9AC8
- ADD R12, R3, #0x1400
- LDR R3, [R1]
- STR R12, [R0]
- STR R12, [R2]
- STR R3, [R1,#4]
- MOV R12, #0
- STR R12, [R3,#0xC]
- LDR R3, [R1,#4]
- LDR R0, =dword_20A9AAC
- STR R12, [R3,#0x10]
- LDR R12, [R2]
- LDR R3, [R1,#4]
- STR R12, [R3,#4]
- LDR R0, [R0]
- LDR R2, [R2]
- ADD R3, R0, #0x140000
- LDR R0, [R1,#4]
- SUB R1, R3, R2
- STR R1, [R0,#8]
- POP {R3,PC}
I modified this to #0x160000 as well.
Conclusion
Overall, my research results are largely based on the work of my seniors. The solutions to several issues were somewhat accidental, but there were still some gains for me. The subsequent work will mainly involve translation. However, researching how to localize the game into Chinese is much more interesting than simply translating texts.
The related build scripts have been open-sourced on GitHub.