好久没动《宝可梦》第四世代汉化修正项目了,最近重新研究了一下珍钻的汉化。因为我对汇编代码并不是很熟悉,还有很多东西没搞懂,但还是姑且先写一下目前的进展,抛砖引玉一下。
ACG汉化组对字库的修改
字库问题是首先需要解决的问题。白金和心魂的字库问题实际上已经被ACG汉化组解决了,但是珍钻的字库问题一直没能得到解决。如果把白金的字库直接用在珍钻上,会显示不出来;而YYJoy汉化组不知道用了什么技术,即使是把他们制作的ROM解包后重新打包都会出现问题。在分析了pret项目提供的逆向工程代码并对比了日版游戏和ACG汉化版游戏的arm9.bin后,我发现了问题所在。
珍钻、白金、心魂使用的字库是同一个格式,都是SimpleFontTable格式,这个格式里保存了m_nItemsCount这个参数,也即字体文件中包含的字符个数。但是在白金和心魂的汉化版中,这个参数实际上是小于字符个数的,因此在我的工具中也将这个参数写死为了0x01FD(后来改为了0x0200)。一开始我不是很明白为什么汉化版要这么做。在对比了日版白金和ACG汉化版的arm9.bin后,我发现有两处修改;同时参照了美版的arm9.bin和pret/pokeplatinum项目,修改的地方在src/unk_020232E0.c这个文件:
复制代码- static void sub_0202343C (UnkStruct_02023350 * param0, u32 param1)
- {
- u32 v0 = param0->unk_0C * param0->unk_5C.unk_08;
- param0->unk_10 = Heap_AllocFromHeap(param1, v0);
- param0->unk_04 = sub_020234BC;
- NARC_ReadFromMember(param0->unk_54, param0->unk_58, param0->unk_5C.unk_00, v0, param0->unk_10);
- }
复制代码- void sub_020234A0 (const UnkStruct_02023350 * param0, u16 param1, UnkStruct_02002328 * param2)
- {
- if (param1 <= param0->unk_5C.unk_08) {
- param1--;
- } else {
- param1 = 0x1ac - 1;
- }
- param0->unk_04(param0, param1, param2);
- }
但是这样还是看不懂,我又对照了心魂的pret/pokeheartgold项目,相应代码在src/font_data.c这个文件:
复制代码- static void InitFontResources_FromPreloaded(struct FontData *fontData, HeapID heapId) {
- u32 size = fontData->glyphSize * fontData->header.numGlyphs;
- fontData->narcReadBuf = AllocFromHeap(heapId, size);
- fontData->uncompGlyphFunc = DecompressGlyphTiles_FromPreloaded;
- NARC_ReadFromMember(fontData->narc, fontData->fileId, fontData->header.headerSize, size, fontData->narcReadBuf);
- }
复制代码- void TryLoadGlyph(struct FontData *fontData, u16 glyphId, struct GlyphInfo *ret) {
- if (glyphId <= fontData->header.numGlyphs) {
- glyphId--;
- } else {
- glyphId = 428 - 1;
- }
- fontData->uncompGlyphFunc(fontData, glyphId, ret);
- }
简直就是一模一样,有了函数名和变量名就很清楚了,函数void TryLoadGlyph()的fontData->header.numGlyphs对应的就是前面的m_nItemsCount(字符总数),原本的代码里比对glyphId比字符总数小的时候会返回0x1ac - 1,查码表,01AC对应的字符是?,也就是说,如果要显示的字符超过了字库中的字符总数,就显示?。而在ACG汉化版中,似乎是把条件跳转改为了强制跳转,也即这个判断失效,不管glyphId是多少都会根据glyphId显示。而函数void InitFontResources_FromPreloaded()则是把DecompressGlyphTiles_FromPreloaded的引用改为了DecompressGlyphTiles_LazyFromNarc,也就是把预加载改为了懒加载,也即只有在需要显示的时候才会加载字库,而不是一开始就加载字库,可以减少游戏的内存占用。根据我的测试,如果修改字库文件的m_nItemsCount,游戏会在打开训练家卡片时死机,大概就是内存占用过多的原因。
除此之外还有一处相关的代码:
复制代码- static u32 GetGlyphWidth_VariableWidth(struct FontData *fontData, int glyphId) {
- if (glyphId < fontData->header.numGlyphs) {
- return fontData->glyphWidths[glyphId];
- } else {
- return fontData->glyphWidths[428 - 1];
- }
- }
这里u32 GetGlyphWidth_VariableWidth()是获取字符的宽度,如果字符超过了字库中的字符总数,就返回?的宽度。ACG汉化的白金版没有修改此处的代码,所以在字库中需要修改?的宽度为中文汉字的宽度,否则汉字会显示不完全。
照葫芦画瓢
既然知道了ACG汉化组是怎么改的,我本以为可以照葫芦画瓢,对珍钻的arm9.bin也进行类似的改动。但遗憾的是,因为珍钻是最早的作品,它加载字库的代码与后续作品都不一致,甚至日版与美版的代码都不一致。我不太懂如何反汇编,所以只能先在美版的珍钻上动刀。
同样参照pret/pokediamond项目,相关代码在arm9/src/unk_02021590.c文件中:
复制代码- void InitFontResources_FromPreloaded(struct FontData * ptr, HeapID heapId)
- {
- u32 r4 = ptr->glyphSize * ptr->gfxHeader.numGlyphs;
- ptr->narcReadBuf = AllocFromHeap(heapId, r4);
- ptr->uncompGlyphFunc = DecompressGlyphTiles_FromPreloaded;
- NARC_ReadFromMember(ptr->narc, ptr->fileId, ptr->gfxHeader.headerSize, r4, ptr->narcReadBuf);
- }
复制代码- void TryLoadGlyph(struct FontData * ptr, u32 param1, struct UnkStruct_02002C14_sub * ptr2)
- {
- if (param1 <= ptr->gfxHeader.numGlyphs)
- ptr->uncompGlyphFunc(ptr, (u16)(param1 - 1), ptr2);
- else
- {
- ptr2->width = 0;
- ptr2->height = 0;
- }
- }
复制代码- int GetGlyphWidth_VariableWidth(struct FontData * ptr, int a1)
- {
- return ptr->glyphWidths[a1];
- }
第一个函数void InitFontResources_FromPreloaded()与上面类似,改成InitFontResources_LazyFromNarc即可。第二个函数void TryLoadGlyph()有些复杂,珍钻在判断param1大于ptr->gfxHeader.numGlyphs之后,直接令字符的宽度和高度为0,这也就解释了为什么把白金的字库直接放到珍钻里会显示不出来而不是显示?。第三个函数int GetGlyphWidth_VariableWidth()也需要修改为与ptr->gfxHeader.numGlyphs对比后返回?的宽度。相应的修改见此处。
搞定了字库之后,文本其实很好解决了,之前修改白金和心魂的时候已经有了比较成熟的工具,直接套用即可。只不过美版比日版多出来了几个文本,需要补全。
文本和字库解决了,但游戏里还有一些日版与美版不同的代码逻辑需要处理。在字符宽度方面,日版用的是宽字符,美版用的是窄字符,视觉上略有区别。虽然可以强制让美版显示日版的宽字符,但由于字符宽度的问题,一些地方会出现显示错位的情况,例如宝可梦图鉴:
 宝可梦图鉴字符有覆盖
宝可梦图鉴字符有覆盖
移植到日版
虽然日版和美版的代码不完全一样,但好在也不是完全不一样。正好我看到了一篇关于修改NDS ROM的文章,里面提到了使用IDA和插件。于是我找到了一个能用于IDA Pro 7.6+版本的插件nds_ida,可以用于将arm9.bin转换成汇编指令。
首先根据特征字节码49 1E 09 04大致定位到TryLoadGlyph()这个函数的位置CODE:0202296C,然后在这个函数的附近可以找到其它相关函数。虽然函数的顺序略有不同,具体实现方法也有差异,不过总体来说还是能根据特征步骤找到日版与美版的对应函数。
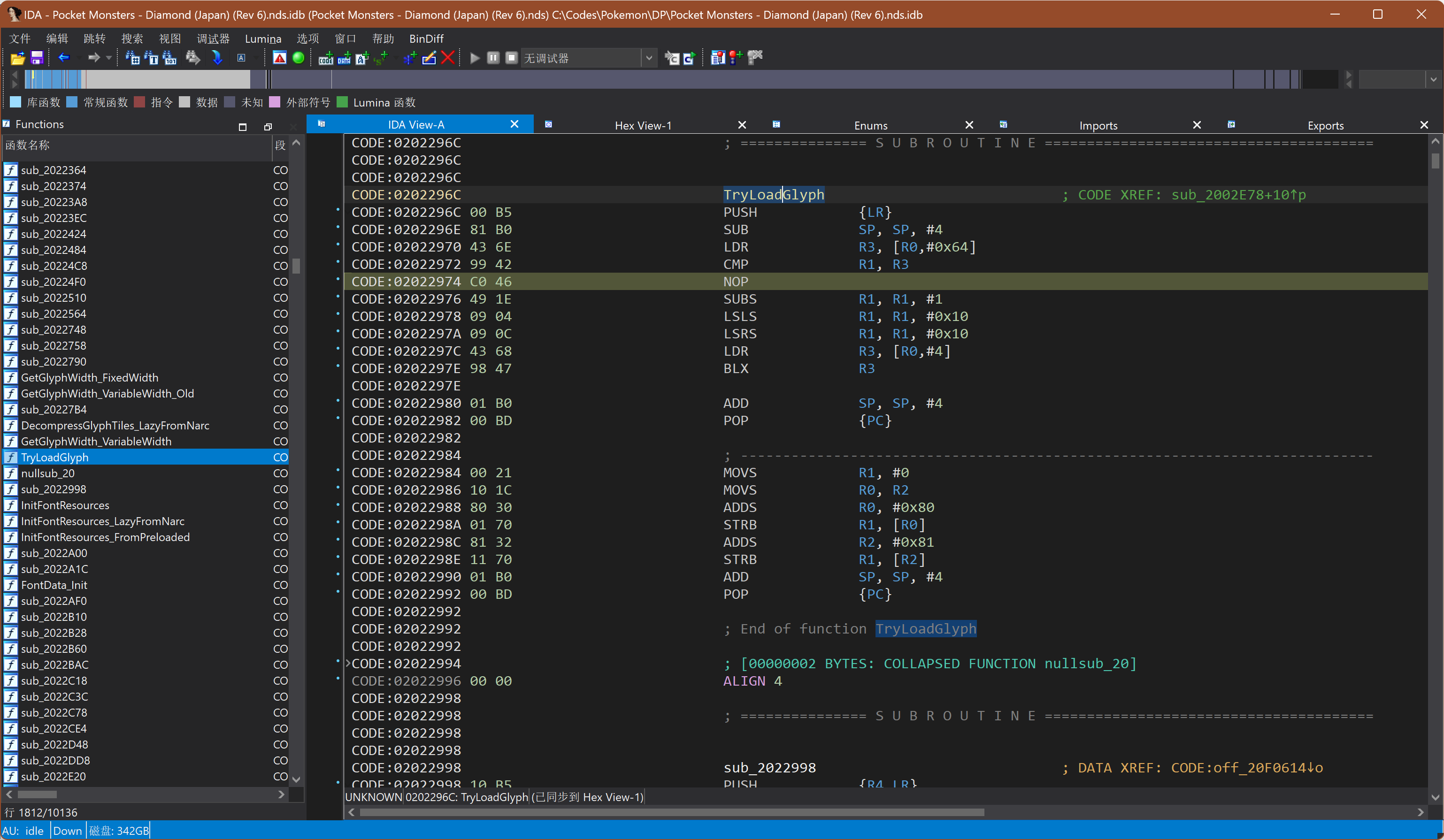 根据pret对美版的函数命名修改了日版的命名
根据pret对美版的函数命名修改了日版的命名
接下来的修改就比较简单了,和上面一一对应。只不过GetGlyphWidth_VariableWidth()这个函数需要扩容,而恰好InitFontResources_FromPreloaded()这个函数不需要调用了,因此可以把前者的地址修改到后者这里,覆盖原有的代码即可。修改后的arm9.bin见此处。