« 《超级碧姬公主》汉化笔记(一):文本和字库分析
« 《超级碧姬公主》汉化笔记(二):字库扩容
上回书说到,游戏里的字库和文本都已经解决了。接下来要做的就是分析图片了。
从内存中转储出图片数据
一进到游戏里,首先看到的是游戏Logo,就拿它来开刀吧。然而,在拆包出来的文件里寻找title、logo之类的文件名都没有找到可能是Logo的文件,结合前面文本和字库都在可执行文件里的情况分析,或许Logo的数据也在可执行文件里?
在前两篇汉化笔记中,我们定位文本时采用的是文本的Shift-JIS编码搜索。但是要定位图片需要用什么字节数据搜索呢?答案就是——显存数据。关于NDS主机的显存,可以参考BlocksDS上的这篇文章。这里不需要对显存有太多了解(因为我也没完全搞明白),只需要知道显存的内存地址范围是从0x6000000开始的即可。
再次用DeSmuME模拟器打开游戏,当游戏显示Logo时暂停,通过“Tools”→“View Tiles”,然后选择256 colors,可以查看显存中的Tile(图块)数据。非常巧,在下半部分正好就看到了Logo的图片,排列和色板都没错,只不过上半部分似乎有些奇怪的像素。
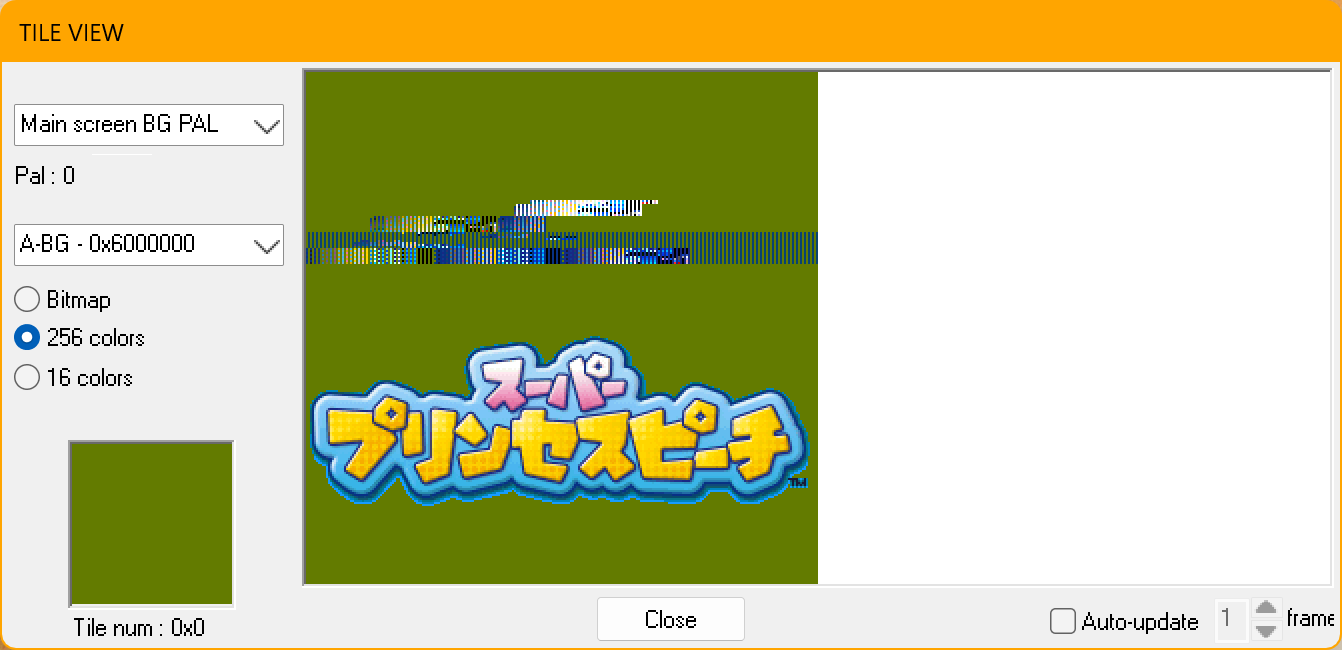 查看Tile数据
查看Tile数据
先不考虑奇怪的像素,如何查看Tile对应的内存数据呢?在第一篇笔记中我给出了DeSmuME内存转储文件的结构,其中似乎没有Tile对应的内存数据。于是,接下来用到另一个模拟器——No$GBA。顺带一提,No$GBA模拟器在2025年4月14日久违地更新了一个版本,旧版本的No$GBA在打开这个游戏时会有一些显示错误,最新版本似乎修复了这个问题。
用No$GBA的Debug版本打开游戏,同样在出现Logo时暂停,在左下角的内存区域单击右键→“Goto…”,跳转到6000000(输入值默认为十六进制),然后选择“Utility”→“Binarydump to .bin File”,输入10000,然后保存为文件。
为了确认导出的内存数据包含Logo,用CrystalTile2打开数据,设置为Tile视图、宽度256、高度256、Tile颜色格式GBA 8bpp、绘图模式ObjH-1234,就可以看到图片数据了:
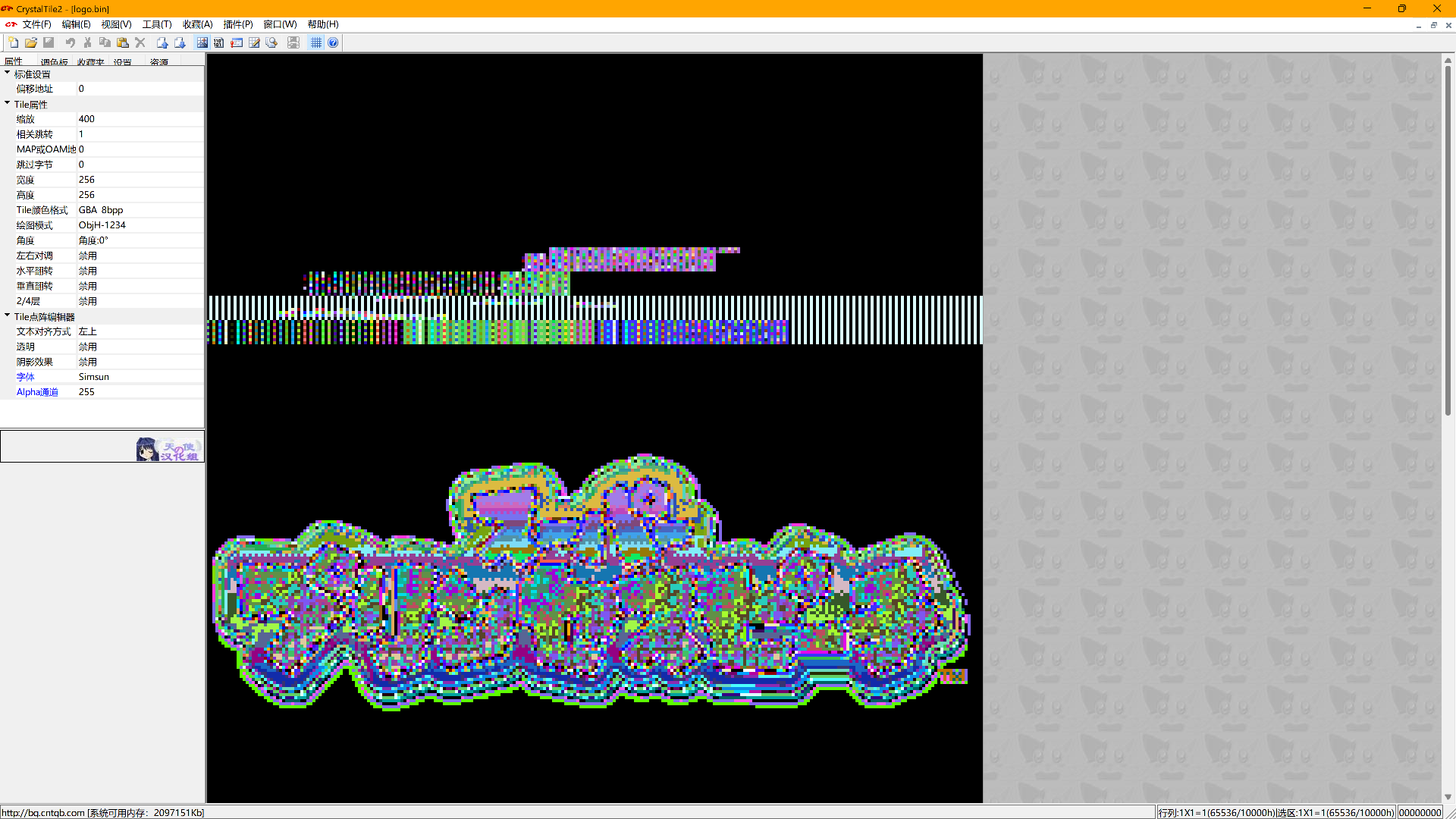 包含Logo的数据
包含Logo的数据
可以看出来虽然调色板有错误(关于调色板的处理方法一会再说),但是图片数据是正确的。使用HxD打开转储文件后,选取二进制数据中的一段非零数据7A 76 73 6D 64 45 22(位于转储文件的0x84B8处,即内存地址的0x60084B8)在ROM中查找——没有找到!这是怎么回事呢?
在ROM中寻找原始图片数据
既然Logo的Tile数据在显存中,那么肯定有一个地方把它加载到显存。回到游戏中,继续打开DeSmuME模拟器,重启游戏,使用“Tools”→“View Memory”,在0x60084B8这个内存地址下一个写入断点(No$GBA模拟器也可以下内存断点,但我用DeSmuME比较顺手)。命中断点后,发现数据是从0x22A1DF8这个地址复制过来的。继续在这里下写入断点,发现命中在了0x2090550处。用IDA对这附近的函数反汇编可以看出大致逻辑:
复制代码- char *__fastcall sub_2090514(char *a1, char *a2)
- {
- char *result; // r0
- unsigned int v3; // t1
- int v4; // r2
- char v5; // lr
- char v6; // t1
- int v7; // r4
- bool v8; // cc
- unsigned int v9; // t1
- int v10; // r3
- char *v11; // r0
- unsigned __int8 v12; // t1
- int v13; // r12
- int v14; // t1
- int v15; // r12
- v3 = *(_DWORD *)a1;
- result = a1 + 4;
- v4 = v3 >> 8;
- while ( v4 > 0 )
- {
- v6 = *result++;
- v5 = v6;
- v7 = 8;
- while ( 1 )
- {
- v8 = v7-- < 1;
- if ( v8 )
- break;
- if ( (v5 & 0x80) != 0 )
- {
- v10 = ((int)(unsigned __int8)*result >> 4) + 3;
- v12 = *result;
- v11 = result + 1;
- v13 = (v12 & 0xF) << 8;
- v14 = (unsigned __int8)*v11;
- result = v11 + 1;
- v15 = (v14 | v13) + 1;
- v4 -= v10;
- do
- {
- __swp((unsigned __int8)a2[-v15], (unsigned int *)a2);
- ++a2;
- v8 = v10-- <= 1;
- }
- while ( !v8 );
- }
- else
- {
- v9 = (unsigned __int8)*result++;
- __swp(v9, (unsigned int *)a2++);
- --v4;
- }
- if ( v4 <= 0 )
- break;
- v5 *= 2;
- }
- }
- return result;
- }
如果对NDS游戏比较熟悉的话,可以从v7 = 8;、if ( (v5 & 0x80) != 0 )猜出来这是一个LZ77解压缩函数。把这个伪代码喂给DeepSeek也可以直接分析出来这个函数的作用。如果在这个函数的入口处下一个断点,然后在命中断点时查看R0寄存器,就能够得到解压前的原始数据地址,即0x21F0078。转储这部分内存后再去ROM中搜索,就能发现原始数据位于overlay_0019.bin这个文件里。
批量寻找图片数据
显然,游戏中不只有Logo这一张图片,如果全都按照上面的流程导出图片的话过于繁琐了。显然,有必要分析图片数据的特征。
上文中已经得到了Logo的原始数据,用HxD打开后可以发现第一个字节是0x10,猜测是LZ10压缩。解压图片数据后可以看到,文件头是NCG\0。由于LZ10压缩的原理是向前查找重复出现的字节序列,而前4个字节必定不会在前面出现,因此可以直接用NCG\0作为特征字节搜索。用HxD搜索NCG\0,可以找到很多个匹配项。于是接下来的工作就是编写代码搜索所有匹配项。另外,LZ10压缩有一个好处就是它会在压缩数据的最开头添加4字节的原始文件大小信息,所以不需要知道压缩数据的实际大小是多少。可以写个脚本批量提取:
复制代码- import os
- import ndspy.lz10
- os.chdir(os.path.dirname(__file__))
- file_list = ["arm9.bin"]
- for file_name in os.listdir("overlay"):
- if file_name.endswith(".bin"):
- file_list.append(f"overlay/{file_name}")
- for file_name in file_list:
- with open(file_name, "rb") as reader:
- data = reader.read()
- output_path = os.path.split(file_name)[-1].rsplit(".", 1)[0]
- os.makedirs(output_path, exist_ok=True)
- offset = data.find(b"NCG\0")
- while True:
- try:
- file_data = data[offset - 5 :]
- file_data = ndspy.lz10.decompress(file_data)
- with open(f"{output_path}/{output_path}_{offset - 5:08X}.ncg", "wb") as writer:
- writer.write(file_data)
- except Exception as e:
- pass
- next_offset = data.find(b"NCG\0", offset + 1)
- if next_offset == -1:
- break
- offset = next_offset
用同样的方法也可以发现调色板的数据与图片数据类似,只不过文件头是NCL\0。并且由于调色板文件比较小,有些文件可能没有压缩,需要进行特殊处理。
将二进制数据转为可编辑的图片
提取出来了图像和调色板的二进制数据,就可以开始写代码将其转换为可编辑的图片了。调色板文件的格式如下,均为小端序:
| 偏移量 |
大小 |
含义 |
0x00 |
0x04 |
文件头,NCL\0 |
0x04 |
0x04 |
颜色数量 |
0x08 |
颜色数量 × 2 |
颜色数据,每2个字节代表一个颜色 |
其中颜色数据的格式是RGB555,即每2个字节的低5位表示红色,中间5位表示绿色,高5位表示蓝色,可以表示为0BBB BBGG GGGR RRRR。代码:
复制代码- def rgb555_to_color(color: int) -> tuple[int, int, int]:
- r = color & 0x1F
- g = (color >> 5) & 0x1F
- b = (color >> 10) & 0x1F
- return (8 * r, 8 * g, 8 * b)
- with open(ncl_path, "rb") as reader:
- palette_data = reader.read()
- magic = palette_data[:4]
- assert magic == b"NCL\0"
- (color_count,) = struct.unpack_from("<I", palette_data, 4)
- colors = []
- for color in struct.unpack(f"<{color_count}H", palette_data[8:]):
- colors.extend(rgb555_to_color(color))
图像数据的格式如下,均为小端序:
| 偏移量 |
大小 |
含义 |
0x00 |
0x04 |
文件头,NCG\0 |
0x04 |
0x04 |
数据大小(需转换) |
0x08 |
转换后的数据大小 |
图像数据 |
数据大小的换算方式如下(参考自0x2002E30处的汇编代码):
复制代码- real_size = (encoded_size & 0xFFFF) * 0x20 * (2 ** ((encoded_size >> 16) & 1))
图像数据与颜色格式相关,若为8bpp格式,则调色板为256色,每个像素点用1个字节表示;若为4bpp格式,则调色版为16色,每2个像素点用1个字节表示。每8×8个像素点构成一个Tile,(通常来讲)Tile采用从左到右、从上到下的顺序排列为图片。对于8bpp格式的图片,转换代码:
复制代码- with open(ncg_path, "rb") as reader:
- tiles_data = reader.read()
- magic = tiles_data[:4]
- assert magic == b"NCG\0"
- (encoded_size,) = struct.unpack_from("<I", tiles_data, 4)
- real_size = (encoded_size & 0xFFFF) * 0x20 * (2 ** ((encoded_size >> 16) & 1))
- tiles = [tiles_data[_ : _ + 64] for _ in range(8, real_size, 64)]
- width = 256
- height = math.ceil(len(tiles) / (width // 8)) * 8
- image = Image.new("RGBA", (width, height))
- x, y = 0, 0
- for tile in tiles:
- tile_image = Image.frombytes("P", (8, 8), tile)
- tile_image.putpalette(colors)
- tile_image = tile_image.convert("RGBA")
- image.paste(tile_image, (x, y))
- x += 8
- if x >= width:
- x = 0
- y += 8
- image.save(output_path)
对于4bpp格式的图片,要增加一步将1个字节拆分为2个字节的步骤:
复制代码- half_bytes = bytearray()
- for byte in tiles_data:
- half_bytes.append(byte & 0x0F)
- half_bytes.append(byte >> 4)
- tiles_data = bytes(half_bytes)
 提取出来的标题Logo
提取出来的标题Logo
nsc文件与Map
到这里还不算结束。标题图片只是最简单的一种情况。从上面提取出来的图上可以看出,图片右下角是缺失的。而且,ncg文件(姑且这么称它)中并没有包含图片长宽的数据。实际上,ncg文件保存的数据确切来说是Tile数据,而要想将Tile显示为图片,还需要知道Tile的排列方式。这里标题Logo的Tile恰好是规则排列的,调色板也恰好是256色,所以我不需要导出排列方式也可以修改图片。而对于一些复杂的图片而言,Tile的排列方式以及每个Tile用到的调色板是必须的,否则将很难手动修改。比如:
 从ncg文件提取的图片
从ncg文件提取的图片
而基于Tile排列方式和调色板提取出来的图片就会是正确的:
 从nsc文件提取的图片
从nsc文件提取的图片
这种保存了Tile的排列方式和调色板的数据被称为Map数据,用DeSmuME模拟器同样可以通过“Tools”→“View Maps”来查看。实际上,游戏里确实保存了Tile的排列方式和每个Tile用到的调色板,文件头是NSC\0,不如就称它为nsc文件吧。其格式如下:
| 偏移量 |
大小 |
含义 |
0x00 |
0x04 |
文件头,NSC\0 |
0x04 |
0x02 |
Tile数量 |
0x06 |
0x02 |
位深,8bpp图像为0x100,4bpp图像为0x0 |
0x08 |
0x01 |
横向Tile数量 |
0x09 |
0x01 |
纵向Tile数量 |
0x0A |
0x02 |
填充字节 |
0x0C |
Tile数量 × 2 |
Tile排列数据 |
每个Tile的数据为2个字节,其中包含了Tile编号、调色板编号、是否X翻转、是否Y翻转的信息,解析方式如下:
复制代码- (temp,) = struct.unpack_from("<H", nsc_data, 0x0C + i * 2)
- tile_index = temp & 0x3FF
- pal_index = (temp >> 12) & 0xF
- flip_x = bool((temp >> 10) & 1)
- flip_y = bool((temp >> 11) & 1)
结束了吗?
当然没有。尽管我们已经分析了ncl、ncg、nsc三种文件格式,然而如何让这三个文件结合起来呢?说实话,我暂时还没什么头绪。这三个文件无论是偏移量、大小还是调用顺序都没什么明显的规律,还需要进一步分析。
此外,nsc通常是背景图,而对于一些小图标,还存在其他的显示方式(OAM)。例如:
 从ncg文件提取的图片
从ncg文件提取的图片
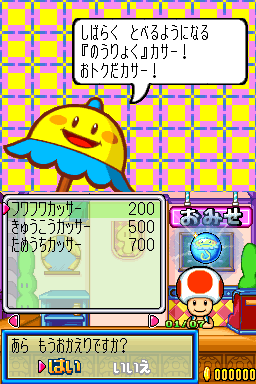 游戏中实际的显示效果
游戏中实际的显示效果
从导出的图片上可以看出,这张图确实包含了游戏截图中“はい”“いいえ”的部分,但是颜色和排列方式都是错误的。当然,可以通过手动对比游戏中的显示效果和导出的图片进行修改,但是这样实在是太麻烦了。通过进一步分析可以知道,游戏中还存在着文件头为NCE\0的nce文件,也与图片的排列有关。不过这种文件格式就更复杂了,如果后续研究有进展的话,我会继续写文章分享。
《超级碧姬公主》汉化笔记(四):数据压缩 »