« 《超级碧姬公主》汉化笔记(一):文本和字库分析
« 《超级碧姬公主》汉化笔记(二):字库扩容
« 《超级碧姬公主》汉化笔记(三):图片数据导出
(封面图由ChatGPT生成)
上回书说到,图片分析有了初步进展。接下来就需要尝试一下能否成功修改图片数据了。
导入图片数据
既然知道了如何导出图片,那么反过来操作不就可以导入图片了吗?理论上来说应该是这样的,然而——由于图片相关的数据被保存在了可执行文件中,这意味着我们修改后的文件大小最好和原始文件大小一致或者更小,这样就不会覆盖掉后面的数据。虽然也可以通过移动数据到新的位置来实现,但这又涉及到地址的修改,比较麻烦。
上篇笔记里提到了,原始数据经过了LZ10压缩,因此在修改了图片之后也要把新的数据压缩回去。ndspy库里提供了LZ10压缩的实现,因此我们可以直接使用它来压缩数据——本以为是这样的,但是ndspy库的LZ10压缩实现得到的压缩率太低,从ROM提取出来的压缩数据经过解压后再压缩得到的数据大小比原来的数据还要大很多,限制了我们的使用。因此,需要寻找其他的LZ10压缩实现。
既然如此,接下来就来研究研究LZ10算法究竟是个什么东西。
LZ10算法及其解压实现
LZ10算法是NDS主机上最常用的一种压缩算法,属于LZ77算法的变种。它的基本思路是通过查找数据中重复的部分来减少数据量。也即,如果一段字节序列在前面曾经出现过,并且字节序列的长度至少为3,那么可以用2个字节来表示重复序列的长度和偏移量,从而减少数据的大小。之所以称之为“LZ10”压缩,是因为压缩后数据的第一个字节必定为0x10。
LZ10算法的大致逻辑如下:压缩后的数据可分为多个组,每组数据第一个字节的8位依次代表了8个数据块的类型。若为0,则将该数据块的1个字节直接复制到输出数据中。若为1,则将该数据块的2个字节作为指令,低12位表示偏移量,高4位表示长度。长度的计算方式为length = (uint >> 12) + 3,偏移量的计算方式为offset = uint & 0xFFF。接下来就可以根据偏移量从输出数据中复制出指定长度的数据了。
 LZ10压缩数据示意图
LZ10压缩数据示意图
在上篇笔记中我给出了解压算法的伪代码,这里给出Python的实现(引自ndspy的实现,基于GPLv3,略有修改):
复制代码- import struct
- def decompress(data: bytes) -> bytes:
- assert data[0] == 0x10, TypeError("This isn't a LZ10-compressed file.")
- decompressed_size = struct.unpack_from("<I", data)[0] >> 8
- out = bytearray(decompressed_size)
- input_pos = 4
- output_pos = 0
- while decompressed_size > 0:
- byte = data[input_pos]
- input_pos += 1
- for bit in range(8):
- if byte & 0x80:
- (temp,) = struct.unpack_from(">H", data, input_pos)
- input_pos += 2
- length = (temp >> 12) + 3
- offset = temp & 0xFFF
- copy_from = output_pos - offset - 1
- for _ in range(length):
- out[output_pos] = out[copy_from]
- output_pos += 1
- copy_from += 1
- decompressed_size -= 1
- if decompressed_size == 0:
- return bytes(out)
- else:
- out[output_pos] = data[input_pos]
- output_pos += 1
- input_pos += 1
- decompressed_size -= 1
- if decompressed_size == 0:
- return bytes(out)
- byte <<= 1
- return bytes(out)
压缩算法的编写与改进
解压算法非常简单,难度在于压缩算法。维基百科上有关于LZ77算法的介绍,其核心思想就是在当前位置下向前查找重复序列,并记录下重复序列的长度和偏移量。对于LZ10算法来说,重复序列的长度范围为3-18,偏移量范围为1-4096,其编码方式大致如下图所示:
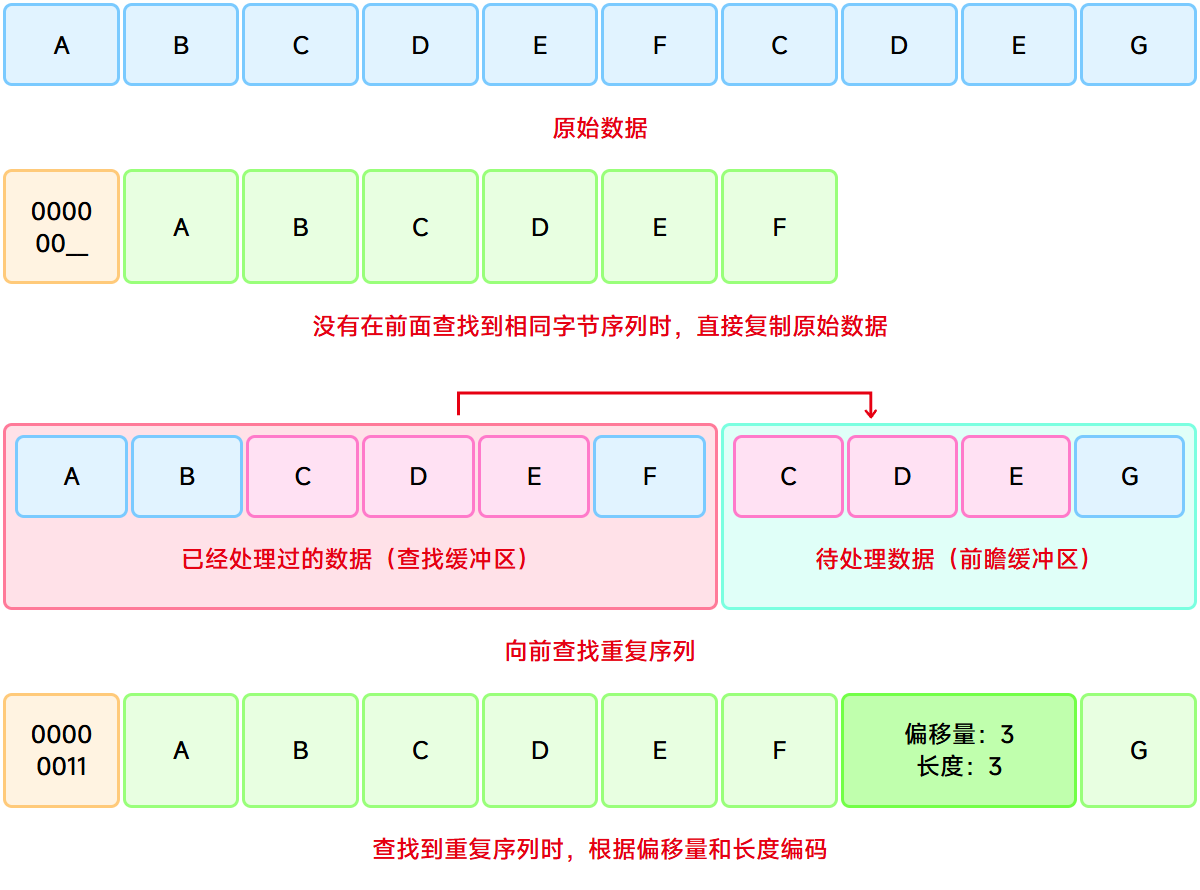 LZ10压缩算法查找过程
LZ10压缩算法查找过程
前面提到了ndspy给出的压缩算法压缩率太低,那么就来分析一下它是怎么实现的。ndspy.lz10.compress调用了_lzCommon.compress函数来实现压缩,而在_lzCommon.compress函数的核心逻辑中,最重要的是查找重复序列的函数compressionSearch。这个函数的实现逻辑如下:
复制代码- maxMatchDiff = 0x1000
- maxMatchLen = 18
- searchReverse = False
- def compressionSearch(pos):
- start = max(0, pos - maxMatchDiff)
- lower = 0
- upper = min(maxMatchLen, len(data) - pos)
- recordMatchPos = recordMatchLen = 0
- while lower <= upper:
- matchLen = (lower + upper) // 2
- match = data[pos : pos + matchLen]
- if searchReverse:
- matchPos = data.rfind(match, start, pos)
- else:
- matchPos = data.find(match, start, pos)
- if matchPos == -1:
- upper = matchLen - 1
- else:
- if matchLen > recordMatchLen:
- recordMatchPos, recordMatchLen = matchPos, matchLen
- lower = matchLen + 1
- return recordMatchPos, recordMatchLen
可以看出,这个函数的核心逻辑是二分查找,查找以当前位置为起始的在前面出现过的最长序列。其中,为了保证查找方向是向前的(避免查找到当前位置,因为从当前位置复制数据没有意义),代码中有一行:matchPos = data.find(match, start, pos)。但是仔细思考可以发现,这样会错过一种特殊情况,即重复序列和自身重叠的情况。例如:
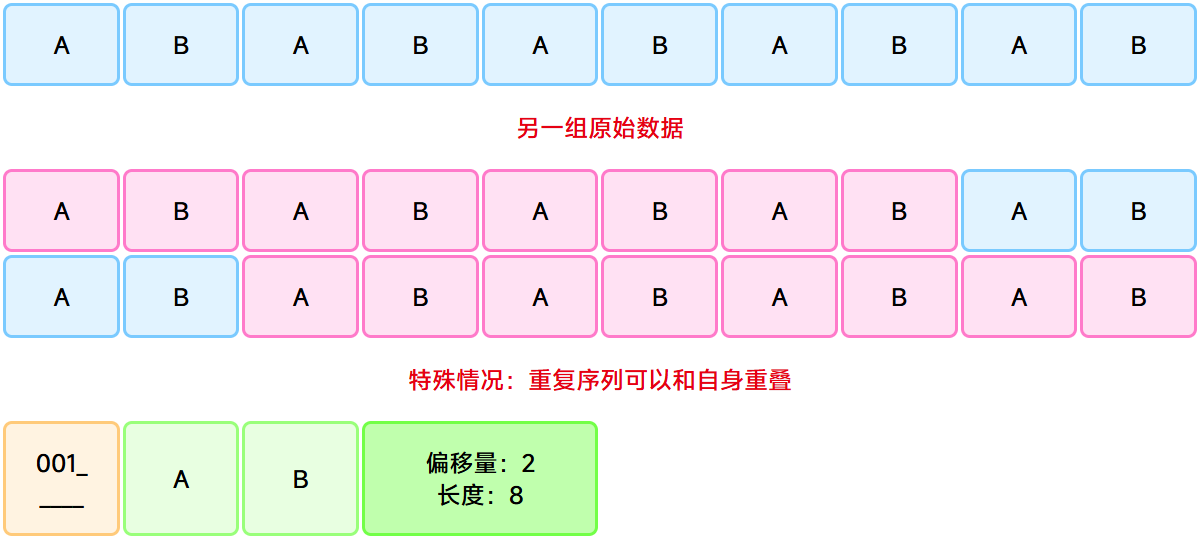 重复序列和自身重叠的特殊情况
重复序列和自身重叠的特殊情况
维基百科中也提到了这种情况:
许多关于LZ77算法的文档都将长度距离对描述为从滑动窗“复制”数据的命令:“在缓冲区中回退距离个字符然后从那点开始复制长度个字符。”尽管对于习惯于指令式编程的人们来说很直观,但是它仍然使得人们很难理解LZ77编码的一个特点:也就是说,长度距离对中的长度超过距离这样一种情况不仅是可接受的而且还是经常出现的情况。作为一个复制命令,就会让人费解:“回退一个字符然后从那点开始复制七个字符。”但是如果缓冲区中只有一个字符的话那该如何复制七个字符呢?然而将长度距离对看作对于特性的描述就可以避免这种混淆:后面的七个字符与前面的七个完全相同。这就意味着每个字符都可以通过在缓冲区找到确定下来:即使在当前数据对解码开始的时候所要查找的字符并不在缓冲区中也可以。通过这个定义,这样的数据对将是距离字符序列的多次重复,也就是说LZ77成了一个灵活容易的行程长度编码形式。
(维基百科:LZ77与LZ78,CC BY-SA 4.0)
例如,测试一段特殊字节序列:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00,采用ndspy的压缩算法得到的压缩数据为:10 13 00 00 1C 00 00 00 00 02 30 05 40 0B,但实际上还可以被简化为10 13 00 00 40 00 F0 00。可以简单地测试一下:
复制代码- import ndspy.lz10
- uncompressed = bytes.fromhex("00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00")
- compressed_1 = bytes.fromhex("10 13 00 00 1C 00 00 00 00 02 30 05 40 0B")
- compressed_2 = bytes.fromhex("10 13 00 00 40 00 F0 00")
- assert ndspy.lz10.decompress(compressed_1) == uncompressed
- assert ndspy.lz10.decompress(compressed_2) == uncompressed
那么该如何修改呢?其实很简单,把matchPos = data.find(match, start, pos)改成matchPos = data.find(match, start, pos + matchLen - 1)即可,这样就能在查找重复序列时考虑到重叠的情况了。
结尾
在NDS游戏中,除了最常见的LZ10压缩外,还有其他类型的LZ压缩算法,例如《Another Code 两种记忆》使用了文件头为“12 3D DA 01”的压缩方式。这些压缩方法核心原理都是类似的,只是表示重复序列长度和偏移量的方法可能会有所差异。在NDS后期的一些游戏中,arm9.bin也被压缩了,这采用的是一种被称为BLZ压缩的算法,B可能代表Backward,表示向后查找重复序列。ndspy也有对BLZ压缩的实现,即ndspy.codeCompression.compress(),感兴趣的话可以去看看。
到这里,压缩率不够的问题终于被解决了。然而,对于nce文件的研究还没有进展,这就留待以后再深入分析了。