汉化完了《数码宝贝物语 遗失的进化》,群里有人问接下来该做什么,提到了这个游戏。于是就来研究一下。
文本提取
拆包的流程和大多数NDS游戏一样,这里就不重复说了。拆包之后照例在/data/文件夹下查找可能是文本的文件,但是搜了一圈也没有找到。怎么办呢?直接运行试试。
打开DeSmuME模拟器,在出现文本时暂停,使用“Tools”→“View Memory”→“Dump All”可以把内存转储出来,得到一个15.0 MiB的文件。根据DeSmuME的源代码,内存数据在转储文件和NDS主机内存中的对应关系大致如下表所示:
| 转储文件地址起始 |
大小 |
含义 |
0x000000 |
8192 KiB |
ARM9 主内存 |
0x900000 |
16 KiB |
ARM9 DTCM |
0xA00000 |
32 KiB |
ARM9 ITCM |
0xB00000 |
656 KiB |
LCD |
0xC00000 |
2 KiB |
调色板 |
0xD00000 |
64 KiB |
ARM7 WRAM |
0xE00000 |
64 KiB |
ARM7 Wifi RAM ? |
0xF00000 |
32 KiB |
ARM9/ARM7共享 WRAM |
(注:对于0xC00000处的数据,源代码中的注释说是OAM,但实际上转储的数据是调色板,这里给出的是实际转储出的数据)
然后用HxD打开搜索文本序列。考虑到这游戏是2005年发售的,编码方式很可能用的是Shift-JIS,所以将要找的文本序列转成Shift-JIS编码然后搜索。
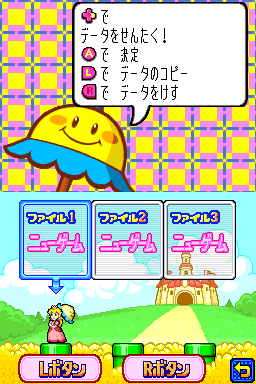 游戏中最初的一处文本
游戏中最初的一处文本
作为示例,根据图片里的显示搜索“データのコピー”,转成Shift-JIS编码之后是83 66 81 5B 83 5E 82 CC 83 52 83 73 81 5B。搜索这个字节序列,果然在内存中找到了,位于0xEDA6A位置:
复制代码- Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
- 000EDA60 01 07 81 40 81 40 82 C5 81 40 83 66 81 5B 83 5E ...@.@‚Å.@ƒf.[ƒ^
- 000EDA70 82 CC 83 52 83 73 81 5B 0A 1A 06 05 00 01 08 81 ‚̃Rƒs.[........
- 000EDA80 40 81 40 82 C5 81 40 83 66 81 5B 83 5E 82 F0 82 @.@‚Å.@ƒf.[ƒ^‚ð‚
往上翻一翻,可以看到一个熟悉的字节序列:MESGbmg1,这是NDS游戏很常用的一个文本格式,有现成的工具可以用。因为我喜欢用Python写脚本,所以可以直接调用ndspy库来解析。那么,文本究竟藏在了什么地方呢?
如果对NDS的内存结构比较熟悉的话,其实可以发现这个内存地址是比较靠前的。而这个游戏的arm9.bin有1.36 MiB,换成十六进制是0x15DBA4,所以这些文本实际上是被硬编码在了arm9.bin里。NDS早期的很多公司估计还保留了GBA时代的开发习惯,喜欢把数据都放在可执行文件里,之前研究过的《Another Code 两种记忆》也是如此。
既然已经知道了文本的位置,提取也变得简单了。直接在arm9.bin中搜索MESGbmg1这个文件头,由于文件头的后面4个字节就是大端序编码的文件长度,所以很轻松就能全部提取出来。
字库分析
本以为这游戏文本用了常见格式,字库也会用常见格式。但是我不管是在arm9.bin里找还是在/data/文件夹下找都没找到字库,搜索fnt、font之类的词也没有找到。由于这个游戏的汇编代码里有很多通过寄存器跳转的指令,静态调试有些头疼。怎么办呢?动态调试吧。
上一步找到了文本所在的内存,省了大事了。继续打开DeSmuME模拟器,使用“Tools”→“View Memory”,在0x20EDA6A这个内存地址下一个读取断点。通过“Tools”→“Disassmbler”可以查看汇编代码和寄存器的值。经过一番排查,最后锁定在了0x206E3DC这里,汇编代码是这样的:
复制代码- loc_206E3DC
- LDRB R5, [R1]
- MOV R2, R2, LSL#16
- LDRB R3, [R3, #1]
- MOV R1, R2, ASR#16
- LDR LR, [LR, #0x20]
- ORR R2, R3, R5, LSL#8
最初R1和R3寄存器中的地址都是0x20EDA6A,在这番处理之后,R2寄存器中的值是0x8366,恰好是デ这个字的Shift-JIS编码。为了验证这里是否就是用于文字显示的代码,手动修改这个寄存器的值为0x8396(ヶ),然后点击“Update Registers”保存,取消断点继续运行:
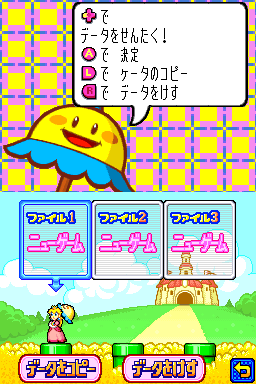 修改寄存器后的运行结果
修改寄存器后的运行结果
显示出来的文字确实修改了,说明这里就是用于文字显示的代码。继续往下追踪,直到发现0x206EDD8这处函数:
复制代码- sub_206EDD8
- AND R2, R1, #0xFF
- MOV R1, R1, ASR#8
- SUB R3, R2, #0x40
- AND R2, R1, #0x3F
- MOV R1, #0xC0
- MLA R1, R2, R1, R3
- MOV R1, R1, LSL#16
- LDR R2, [R0, #8]
- MOV R0, R1, LSR#16
- LDR R0, [R2, R0, LSL#2]
- BX LR
来分析一下这段代码做了什么:
寄存器R0和R1分别是这个函数的两个输入参数,R0 = 0x229CCC8,R1 = 0x8396。然后将R1的低8位和高8位分别运算,低8位(R3)减去0x40,高8位(R2)和0x3F做与运算(相当于取了低6位)。接着将R3乘以0xC0,然后加上R2,保存在R1中。也就是说,这里实际上是将字形的偏移量计算出来了。随后将[R0 + 8]这个地址处的指针读取到R2寄存器(0x20EE3A8),然后读取[R2 + R1 * 4]这个位置的数据作为函数返回值(0xEDF8)。伪代码:
复制代码- uint32_t func(void *struct_ptr, uint32_t encoded_index) {
- uint8_t low = encoded_index & 0xFF;
- uint8_t high = (encoded_index >> 8) & 0x3F;
- int32_t adjusted_low = low - 0x40;
- uint32_t index = adjusted_low + high * 0xC0;
- uint32_t *array = *( (uint32_t**)( (char*)struct_ptr + 8 ) );
- return array[ (uint16_t)index ];
- }
为什么要这么处理呢?查看Shift-JIS的编码方式可知,双字节编码时高8位的范围应该是0x81-0x9F和0xE0-0xEF,低8位的范围应该是0x40-0x7E和0x80-0xFC,所以上面的算法相当于是比较节省空间的一种存储方式。但是到这里还没分析完,根据上面的分析,每个字符分配的空间只有4个字节,但是游戏中字符的大小是8x16像素(128像素),至少也要16个字节(128位)才能存储。继续追踪这个函数的返回值,发现了调用它的地方:
复制代码- sub_206ED0C
- PUSH {R4, LR}
- LDR R2, [R0]
- MOV R4, R0
- LDR R2, [R2]
- BLX R2
- LDR R1, [R4, #0xC]
- ADD R0, R1, R0
- POP {R4,LR}
- BX LR
这里BLX R2是调用了sub_206EDD8这个函数,返回值保存在R0寄存器中。接着读取[R4 + 0xC]这个地址处的指针(0x20EE3A4),然后将这个指针加上R0的值,最后返回(0x20FD19C)。也就是说,实际上上面的顺序保存时保存的数据是另一个偏移量,真正的数据在后面。总结如下:
- 字符编号的计算方式:
index = (low - 0x40) + (high & 0x3F) * 0xC0
- 字库数据的开始地址:
0x20EE3A4
- 字符偏移量列表的开始地址:
0x20EE3A8(第n个字符的偏移量是0x20EE3A8 + n * 4)
- 字符数据的开始地址:
0x20EE3A4 + 字符偏移量
Shift-JIS双字节编码的第一个可见字符是顿号(、,U+3001),Shift-JIS编码是0x8141。计算可知其编号为0xC1,偏移量的地址为0x20EE6AC,此处的数据为0xC026,因此字符数据的地址为0x20FA3CA。为了验证是否正确,在HxD中查看arm9.bin,果然找到了字符数据:
复制代码- Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
- 000FA3C0 00 00 00 00 00 00 00 00 00 00 08 02 00 00 00 00 ................
- 000FA3D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
- 000FA3E0 00 00 00 00 0C 00 30 00 D0 00 40 03 08 02 00 00 ......0.Ð.@.....
- 000FA3F0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
- 000FA400 00 00 00 00 00 00 F4 01 0C 03 0C 03 F4 01 08 02 ......ô.....ô...
- 000FA410 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
- 000FA420 00 00 00 00 00 00 00 00 3C 00 3C 00 30 00 1C 00 ........<.<.0...
可以看到数据的最前面有2个重复出现的字符序列0x08 0x02(可能代表字符的宽高?),而后面的32个字节便是字符数据。32个字节(256位)存储了8x16像素(128像素)的数据,因此每个像素的位深度是2bpp。采用CrystalTile2载入arm9.bin,设置为Tile视图、偏移地址FA3CA、宽度8、高度16、跳过字节2、Tile颜色格式4色 2bpp、绘图模式Tile、左右对调启用、水平翻转启用,可以看到字符的显示效果:
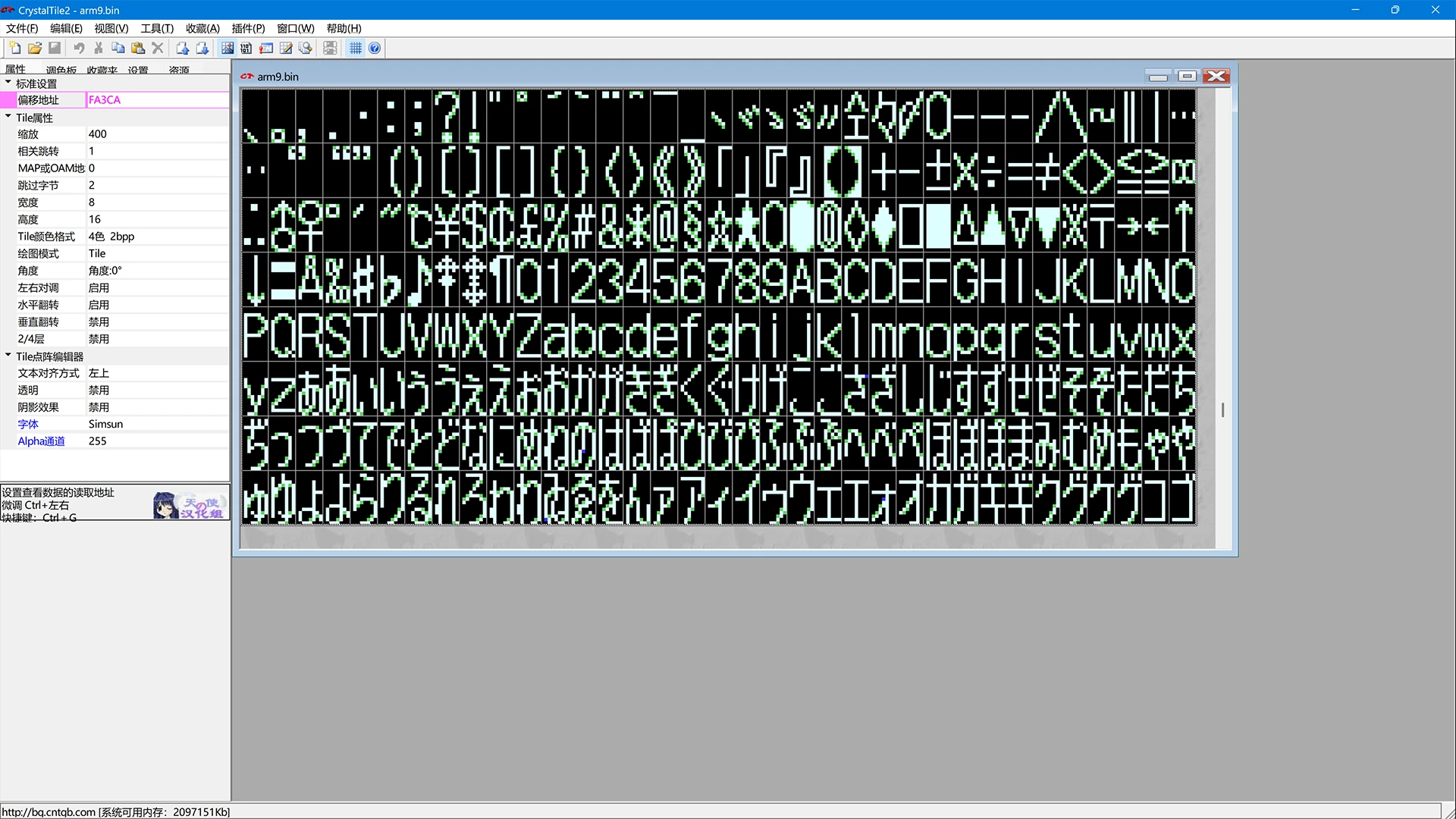 字符数据
字符数据
接下来呢?
知道了字库的保存方式,接下来就可以动手修改了。但是有个问题:由于字库是硬编码在arm9.bin中的,对数据大小比较敏感,原本的字库只保存了448个字符。如果要替换为汉字,这么小的字库肯定是不够用的。那么该怎么办呢?且听下回分解。
《超级碧姬公主》汉化笔记(二):字库扩容 »
《超级碧姬公主》汉化笔记(三):图片导出 »
《超级碧姬公主》汉化笔记(四):数据压缩 »